

PrivateGPTとは
組織の集合的な知識を取り込み、それを解析し、インデックス化し、より深く優れた洞察を得られるよう、そのデータの主権をすべて管理できるとしたらどうでしょうか。それが組織にもたらす力について、興味が湧きませんか。
PrivateGPT(Private Generative Pre-Trainedの略)は、AIコミュニティで大きな注目を集めている比較的新しいAIモデルアーキテクチャです。データ主権に関するいくつかの制限や懸念に対処するように設計されています。
本質的に、PrivateGPT は、モデルのトレーニングと展開中にプライバシーと機密性を維持することに重点を置いた、元の GPT (Generative Pre-Trained) アーキテクチャの修正版です。
PrivateGPT を際立たせる主な機能は次のとおりです。
- 個人データの処理PrivateGPTは準同型暗号化技術を用いて個人データを安全に処理します。つまり、AIモデル自体も機密情報にアクセスできないため、機密性が確保されます。
- 分散トレーニング: 学習中のデータ漏洩リスクを軽減するため、PrivateGPTは複数のマシンが学習プロセスに関与する分散アーキテクチャを採用しています。各マシンはデータの一部を受け取り、他のマシンと連携して勾配を計算します。
- 安全な集約モデルの更新中、PrivateGPT は安全な集約技術を使用して、個々の貢献に関する情報を公開することなく、ローカル モデルを結合します。
PrivateGPT の主な目標は次のとおりです。
- データ保護: トレーニングおよび展開中に機密情報が機密のまま保護されていることを確認します。
- モデルの信頼性: AI モデルの透明性と説明責任を確保しながら、AI モデルの整合性とパフォーマンスを維持します。
- 企業コンプライアンス: AI 開発に対する安全で透明性の高いアプローチを提供することで、規制コンプライアンスを促進します。
Kubernetes 上の PrivateGPT
Kubernetes クラスターで PrivateGPT を実行すると、いくつかの利点が得られます。
そうすることを検討する理由はいくつかあります。
- 拡張性: Kubernetes を使用すると、必要に応じて PrivateGPT のデプロイメントを水平方向 (ノードの追加) または垂直方向 (CPU/メモリ リソースの増加) に拡張できるため、言語モデルがトラフィックの増加や計算要求に対応できるようになります。
- 高可用性: Kubernetes を使用すると、アプリケーションの複数のレプリカをデプロイし、負荷分散を使用して受信リクエストをそれらに分散することで、PrivateGPT サービスを常に利用できるようになります。
- フォールトトレランス: PrivateGPT デプロイメント内の 1 つのノードに障害が発生したり、使用できなくなったりした場合、Kubernetes は自動的に問題を検出し、コンテナを再起動するか、新しいインスタンスに置き換えて、ダウンタイムを最小限に抑え、継続的なサービスの可用性を確保します。
- リソースの分離: Kubernetes はコンテナ間の強力なリソース分離を提供するため、動作の不安定な 1 つのコンテナが過剰なリソースを消費したり、PrivateGPT デプロイメント内の他のコンテナに影響を与えたりするのを防ぐことができます。
- リソースの有効利用: 複数のコンテナを同じホスト ノードにデプロイすると、各コンテナを専用のホストで実行する場合と比べてオーバーヘッドが削減され、リソース使用率が向上します。
- 容易な管理: Kubernetes は、ログ記録、監視、デバッグ ツールなど、PrivateGPT のデプロイメントを管理および監視するための統一された方法を提供します。
- セキュリティ: Kubernetes を使用すると、強力なセキュリティ ポリシーとネットワーク ポリシーを実装して、PrivateGPT サービスへのアクセスを制御し、不正アクセスや悪意のある攻撃から保護することができます。
- 他のサービスとの統合: PrivateGPT サービスをデータベース (PostgreSQL など) やメッセージ キュー (RabbitMQ など) などの他の Kubernetes ネイティブ サービスと統合して、完全な言語処理パイプラインを作成できます。
- 柔軟性Kubernetes を使用すると、さまざまなコンテナ ランタイム (Docker、rkt など) とオーケストレーション エンジン (Helm、kustomize など) から選択して PrivateGPT のデプロイメントを管理できるため、アプリケーションのデプロイメントと管理方法を柔軟に行うことができます。
- 携帯性: Kubernetes を使用すると、PrivateGPT デプロイメントを環境 (開発、本番など) またはクラウド (AWS、GCP、もちろん Zadara など) 間で簡単に移動できるため、言語処理アプリケーションの開発、テスト、デプロイメントが容易になります。
全体として、Kubernetes クラスターで PrivateGPT を実行すると、大規模な言語モデルを展開および運用するための堅牢でスケーラブルかつ管理しやすいインフラストラクチャが提供されます。
論理図:
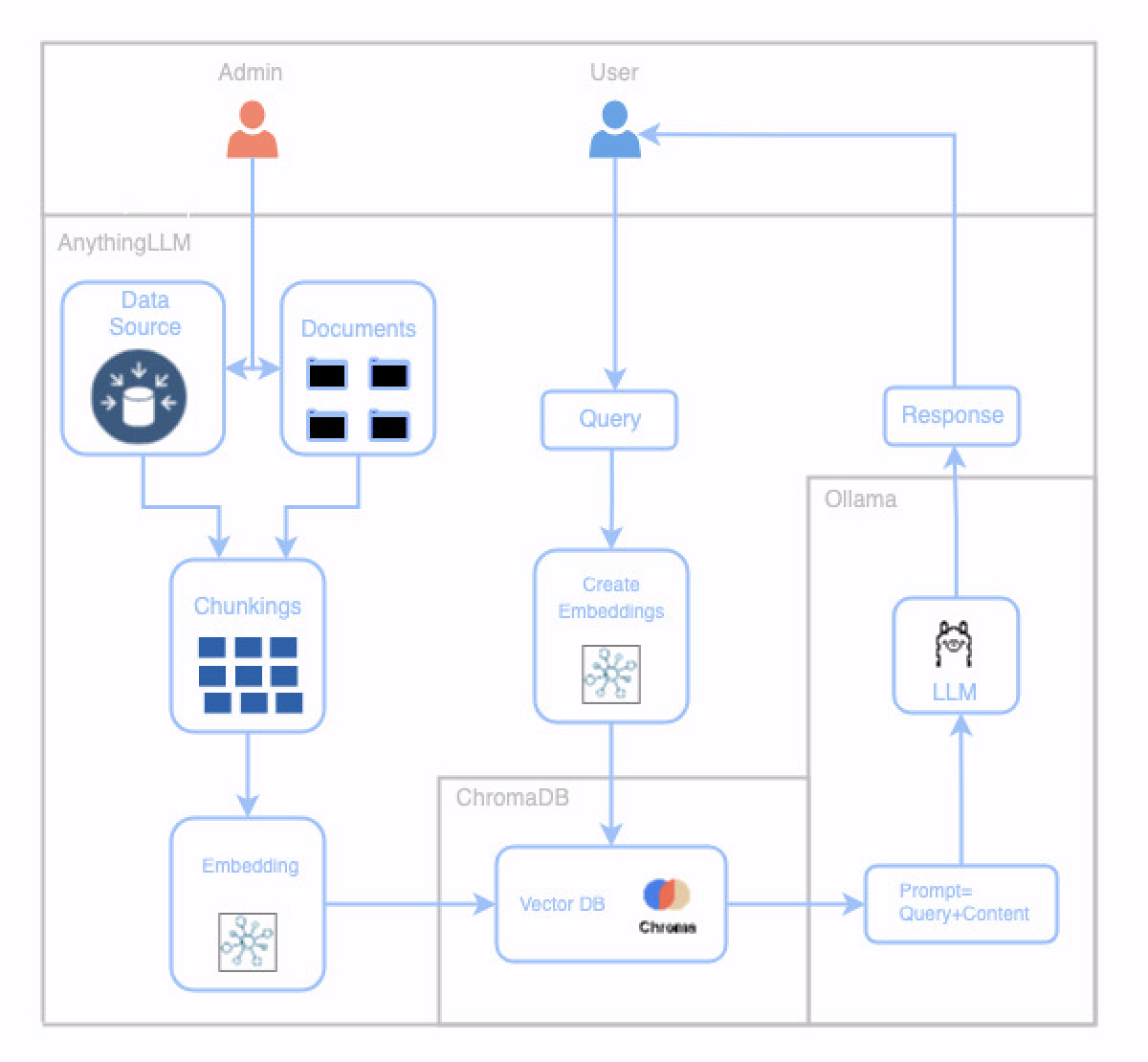
建築:
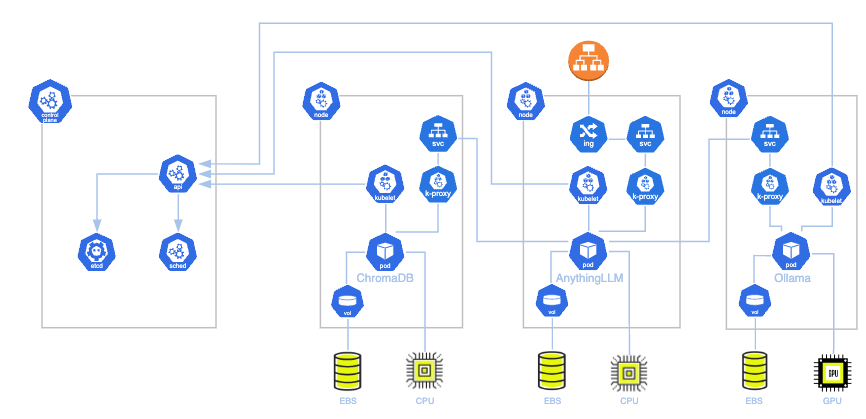
AIデータの課題を理解する
従来のデータベースに大量のテキストデータを保存し、効率的な検索・取得を行うことは、その非構造化の性質上、困難な場合があります。ベクターデータベースは、テキストデータを効率的に比較可能な数値表現(ベクトル)に変換することで、この問題を解決します。しかし、ベクターデータベースを効果的に活用するには、「チャンキング」と「埋め込み」という2つの重要な概念を理解する必要があります。
基本を理解する
詳細に入る前に、2 つの重要な用語を明確にしておきましょう。
- チャンキング: 大きなテキスト ドキュメントを、管理しやすい小さな単位に分割します。
- 埋め込み: テキストを意味を捉える数値表現 (ベクトル) に変換します。
チャンク化と埋め込みの理由
大規模言語モデル(LLM)は情報処理に優れていますが、その容量には限界があります。大規模なデータセットを効果的に処理するには、データセットを小さなチャンクに分割する必要があります。これらのチャンクは埋め込みに変換され、ベクターデータベースを用いた効率的な比較と検索が可能になります。
データ処理に関する考慮事項
- チャンキング:
- チャンクサイズを識別します。 LLMの制限とデータの性質に基づいて、最適なチャンクサイズを決定します。事実に基づくクエリには短いチャンクが適している一方、要約やクリエイティブなテキストの生成には長いチャンクが適している場合があります。
- チャンクの境界を定義します。 テキストを分割する方法を決定します。一般的な方法としては、文、段落、または一定数のトークンで分割する方法があります。
- オーバーラップ: コンテキストの理解と検索精度を向上させるために、チャンクの重複を検討してください。
- 埋め込み:
- 埋め込みモデルを選択してください: 目的の意味表現に基づいて適切な埋め込みモデルを選択してください。一般的な選択肢としては、Sentence Transformers、BERT、RoBERTaなどがあります。
- 埋め込みを生成する: 各チャンクを埋め込みモデルで処理し、その意味を表す数値ベクトルを取得します。
- ベクターデータベースへの保存:
- インデックスの作成: ベクター データベースにインデックスを作成し、埋め込みを効率的に保存および検索します。
- データ挿入: 生成された埋め込みを、対応するチャンク ID またはメタデータとともにベクター データベースに保存します。
ベクターデータベースの役割
ベクトルデータベースは、高次元ベクトルの保存と検索に最適化されています。効率的な類似検索が可能で、与えられたクエリと意味的に類似するチャンクを見つけることができます。これは、正確で関連性の高い情報検索を必要とするLLMアプリケーションにとって非常に重要です。
ユースケースの例
組織の大規模なナレッジベースに基づいて質問応答システムを構築したいとします。
- かたまり: ナレッジベースを小さなセクション (段落など) に分割します。
- 埋め込む: 適切な埋め込みモデルを使用して、各チャンクを数値ベクトルに変換します。
- 格納: 埋め込みとそれに対応するチャンク ID をベクトル データベースに保存します。
- クエリ: ユーザーが質問したら、それをベクトルに変換します。
- サーチ: クエリ ベクトルに基づいて、ベクトル データベースで最も類似したチャンクを検索します。
- 取得と処理: 識別されたチャンクから元のテキストを取得し、LLM を使用して回答を提供します。
主な考慮事項
- チャンクサイズ: さまざまなチャンク サイズを試して、精度と効率の最適なバランスを見つけます。
- 埋め込みモデル: 特定のユースケースとデータ特性に合った埋め込みモデルを選択します。
- ベクターデータベース: アプリケーションに適した機能とパフォーマンスを提供するベクター データベースを選択します。
- 計算リソース: 埋め込み生成は計算コストが高くなる可能性があるため、事前トレーニング済みのモデルの使用またはクラウドベースのサービスの利用を検討してください。
チャンク化、埋め込み、ベクターデータベースを効果的に組み合わせることで、大量のデータを処理し、正確で適切な応答を提供する強力なLLMアプリケーションを構築できます。これにより、従業員の生産性を向上させることができます。また、外部組織に安全な方法でアクセスできれば、アカウントの詳細情報を提供したり、セルフサービスサポート機能を提供したりすることも可能です。
AnythingLLM を使用する理由
なんでもLLM は、カスタムLLMの構築と導入プロセスを簡素化するために設計されたオールインワンプラットフォームです。個人と企業の両方にとって魅力的な選択肢となる、幅広い機能を備えています。
AnythingLLMを使用する主なメリット
- 使いやすさ: コーディングやインフラストラクチャの設定は不要です。プラットフォームは、LLMの構築と展開のためのユーザーフレンドリーなインターフェースを提供します。
- カスタマイズ: 事前トレーニング済みのモデルを微調整したり、カスタム データで独自のモデルをトレーニングしたりできます。
- プライバシー: プラットフォームはコンピュータ上でローカルに実行されるため、データは非公開のままです。
- 費用対効果の高い 多くのクラウドベースの LLM サービスに関連する高い変動コストを回避します。
- 柔軟性: さまざまな LLM とベクター データベースをサポートしており、ニーズに最適なオプションを選択できます。
- RAG 機能: 精度と関連性を向上させる検索拡張生成 (RAG) システムを構築できます。
- AIエージェント機能: タスクを実行し、世界と対話できる AI エージェントを作成できます。
ChromaDB を使用する理由
クロマDB 特に言語モデルやセマンティック検索アプリケーションのコンテキストでは、ベクトル埋め込みを保存および管理するための一般的な選択肢です。
これを使用することを検討する理由は次のとおりです。
シンプルさと使いやすさ
- 直感的なAPI: ChromaDB は、ベクター データベースを簡単に使い始められるようにする簡単な API を提供します。
- 最小限のセットアップ: 大規模な構成なしで、ChromaDB をすぐにセットアップして使用を開始できます。
柔軟性とカスタマイズ
- インメモリまたは永続ストレージ: アプリケーションの要件に応じて、メモリ内ストレージまたは永続ストレージを選択します。
- カスタマイズ可能な埋め込み: 好みの埋め込みモデルを使用して、ChromaDB と統合できます。
- メタデータのサポート: より豊富なクエリとフィルタリングを実現するために、埋め込みとともに追加情報を保存します。
オープンソースとコミュニティ
- 積極的な開発: ChromaDB は、コミュニティが成長し、開発が活発に行われているオープンソース プロジェクトです。
- 費用対効果の高い オープンソース ソリューションであるため、独自のソリューションよりもコスト効率が優れていることがよくあります。
適用例
- セマンティック検索: 意味に基づいて類似のアイテムを検索します。
- レコメンデーションシステム: ユーザーの好みや過去の行動に基づいてアイテムを提案します。
- 質問への回答: クエリに基づいて大規模なデータセットから関連情報を取得します。
- 画像とビデオの検索: 視覚的なコンテンツに基づいて類似の画像や動画を検索します。
他のベクターデータベースとの比較
ChromaDBは有力な候補ですが、具体的なニーズに応じて、Pinecone、Milvus、Weaviateなどの他の選択肢も検討することが重要です。スケーラビリティ、パフォーマンス、クラウド統合、価格といった要素が、決定に影響を与える可能性があります。
Ollama を使用する理由
オラマ は、LLMをローカルで実行しやすくするために設計されたオープンソースプラットフォームです。いくつかの利点があります。
Ollamaを使用する主な利点:
- ローカル制御: データと LLM 環境に対する完全な主権的制御権を保持します。
- オフライン機能: インターネット接続なしでモデルを実行します。プライバシーが重要なアプリケーションや接続が制限されているエリアに最適です。
- カスタマイズ: 特定のタスクまたはドメインに合わせてモデルを微調整します。
- 費用対効果: 多くのクラウドベースのコストと潜在的な API 制限を回避します。
- オープンソース: コミュニティの貢献と透明性の恩恵を受けます。
理想的な使用例:
- プライバシー重視のアプリケーション: データのセキュリティが最も重要である場合。
- オフライン環境: 信頼できるインターネット アクセスがないシナリオ向け。
- カスタムモデルの開発: 特定のタスクに合わせてモデルを微調整します。
- コストの最適化: クラウドベースの LLM に関連する経費を削減したい方向け。
ただし、次の点に注意することが重要です。
- リソースを大量に消費する: LLM をローカルで実行するには、特に大規模に展開する場合は、通常、かなりの計算リソース (GPU) が必要になります。
- モデルのメンテナンス: モデルを最新の状態に保つには時間がかかります。
制御、プライバシー、コスト効率を優先する場合、Ollama はデータからさらなる効率を引き出せる貴重なツールとなります。
TaikunとZadaraを使ったPrivateGPTの導入
これらの手順は、以前のブログ記事で紹介した設定手順をすでに完了していることを前提としています。 ザダラVPC そして設立 Taikun Cloudworks環境
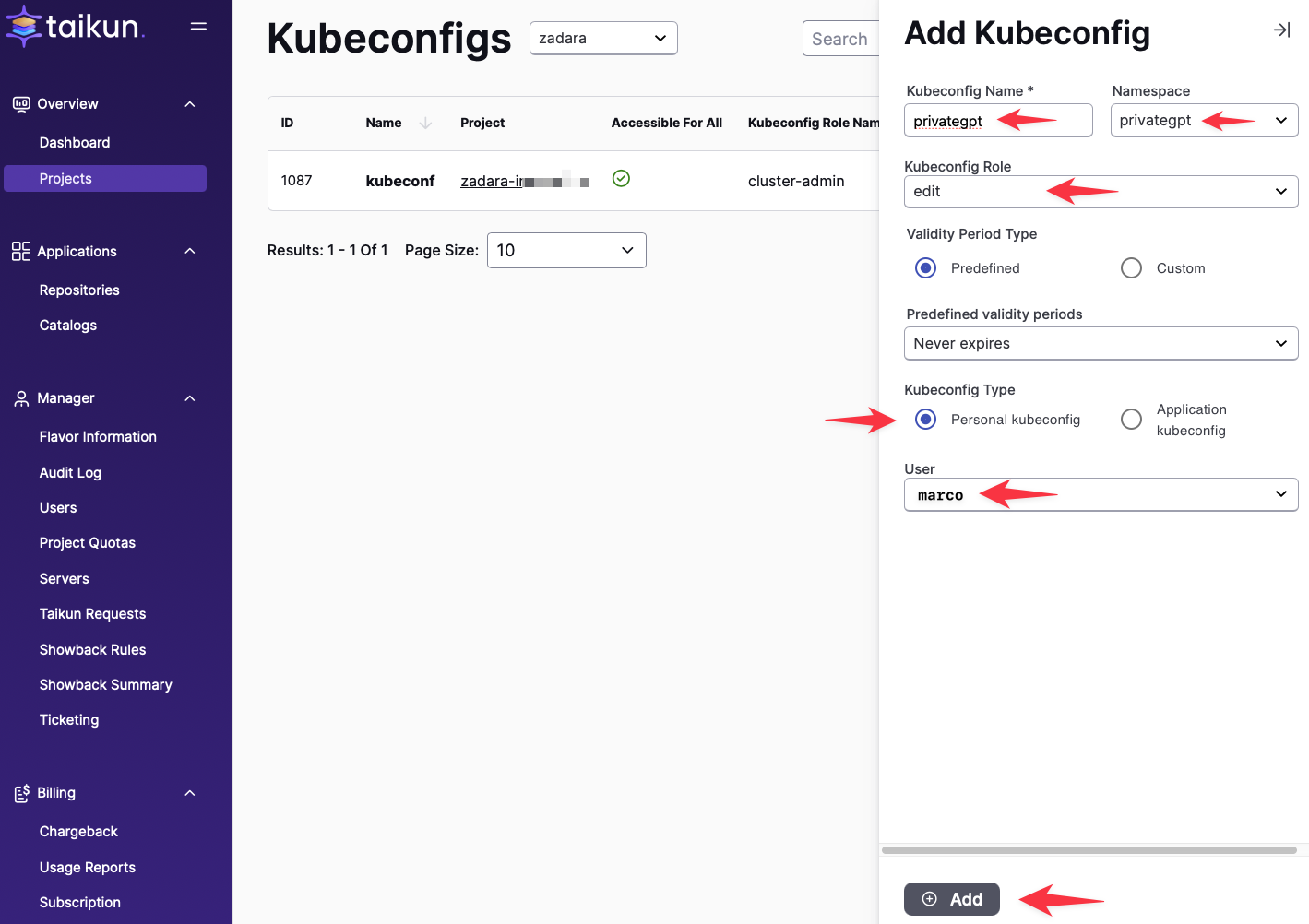
Kubeconfig を生成します:
Zadara zCompute には Elastic Load Balancer (ELB) が組み込まれており、これを利用して AnythingLLM アプリケーションへの外部 HTTPS アクセスを可能にします。残念ながら、この設定は現時点では Cloudworks GUI のみでは実現できず、Kubernetes CLI (kubectl) ツールを使用する必要があります。
開始する前に、kubeconfigファイルが必要です。このファイルは、 .kube/config kubeconfig ファイルの取得と設定に関する詳細な手順については、Kubernetes の公式ドキュメントを参照してください。
Ingress のインストール:
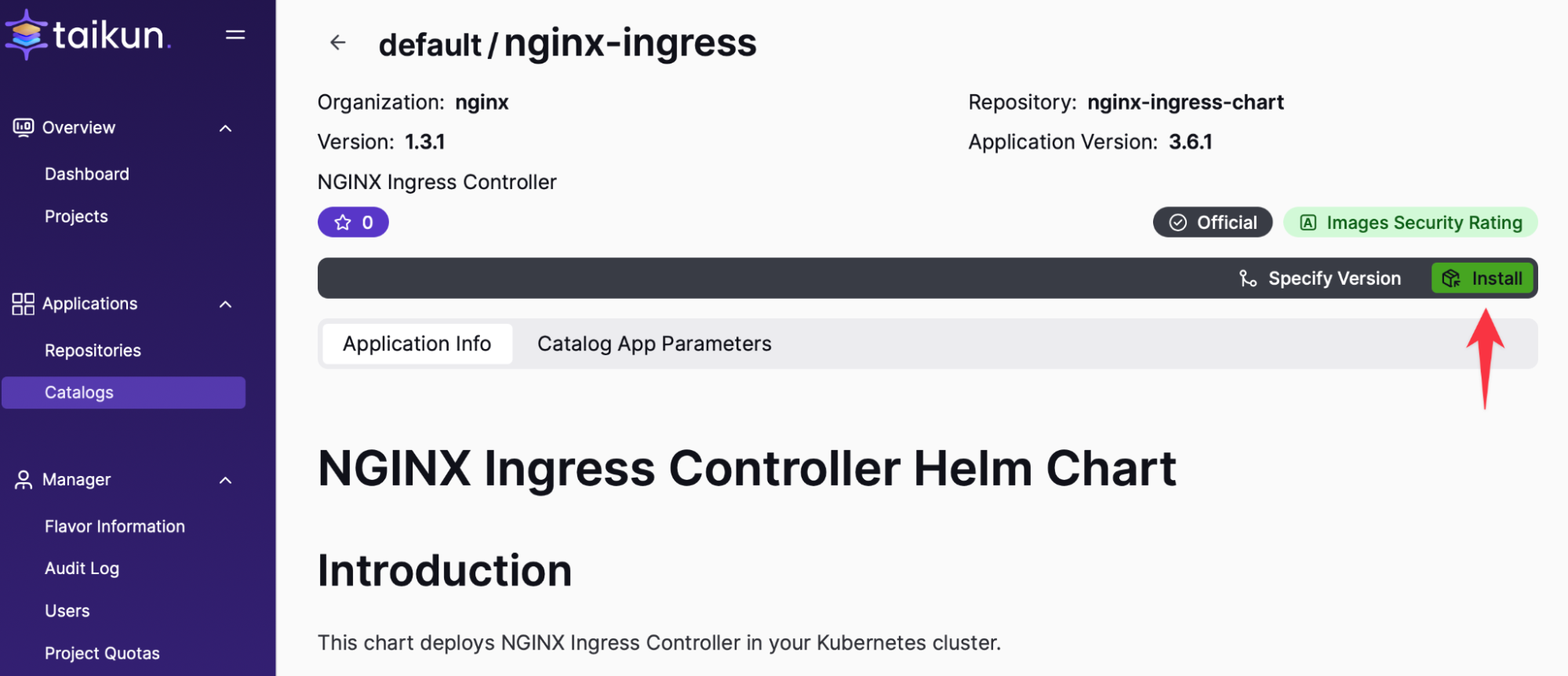
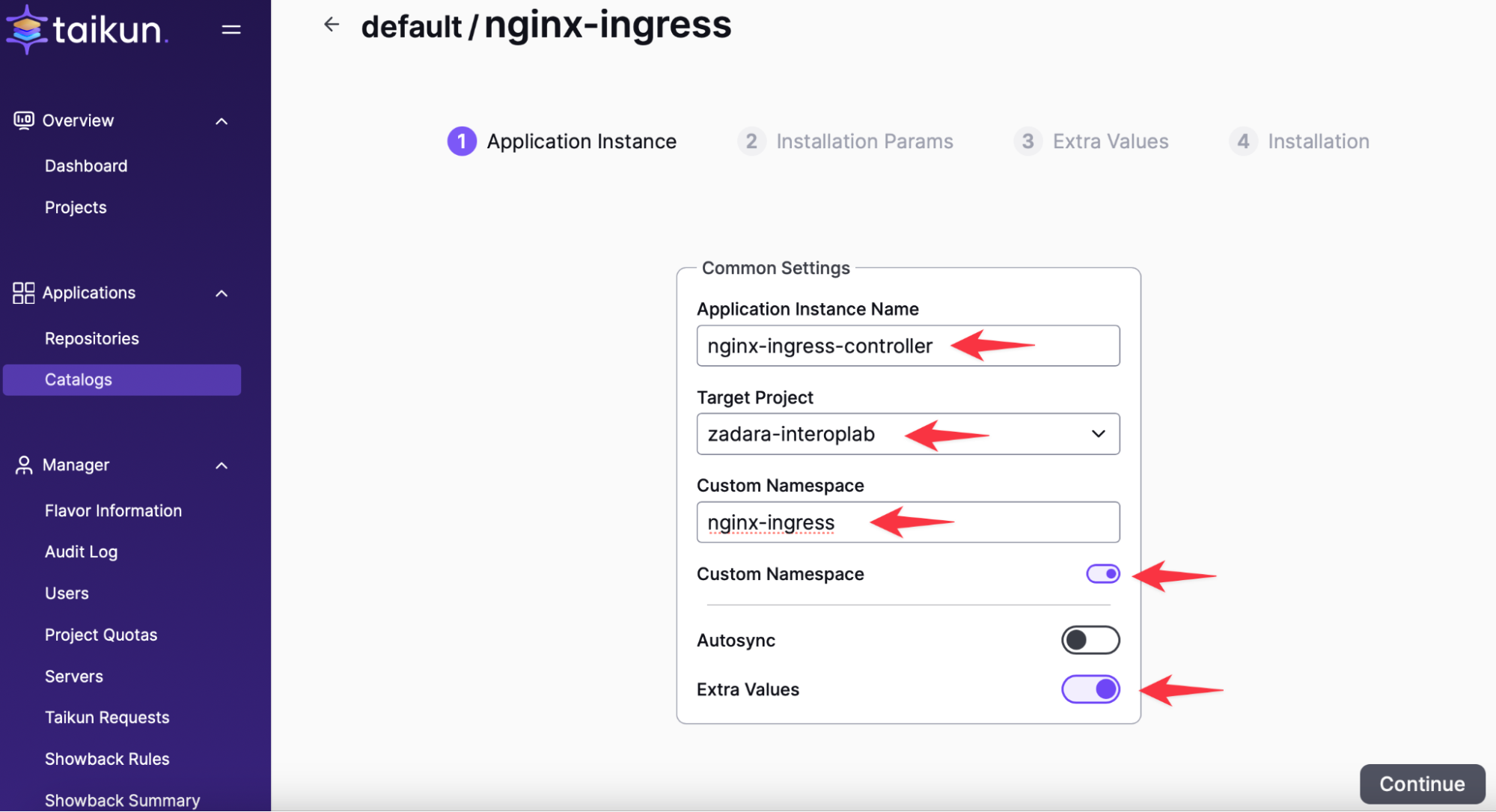
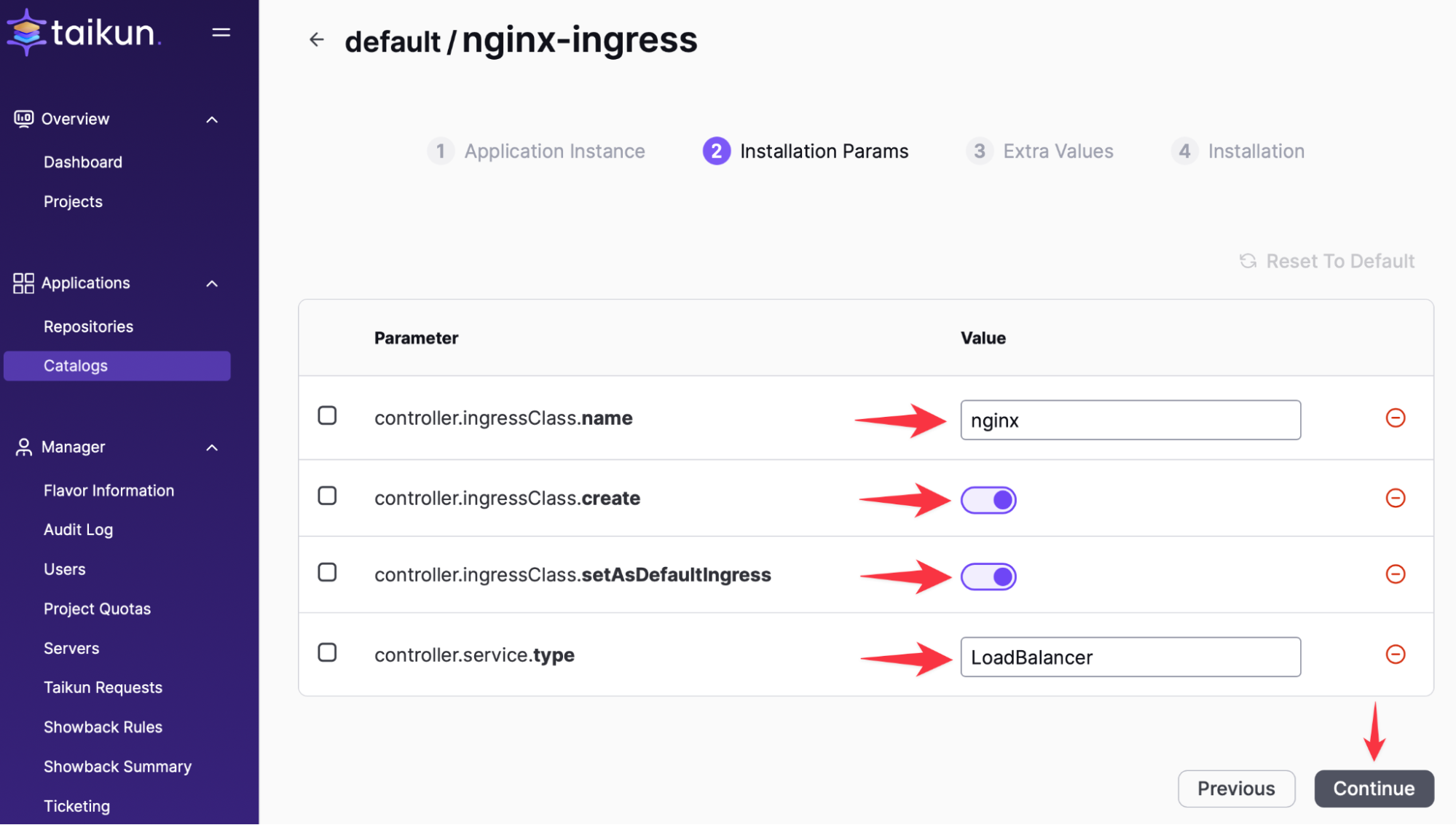

数分後、ロード バランサーは Ingress コントローラーの準備が整います。
次のコマンドで外部 IP を確認できます。
kubectl get svc nginx-ingress-controller-controller -n nginx-ingressこの外部 IP を DNS エントリ (Cloudflare など) に使用します。

httpsを使用するには証明書が必要です。自己署名証明書は簡単に作成できますし、CloudflareなどのDNSプロバイダーから取得することもできます。
openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-out your-cert.crt -keyout your-key.key \
-subj "/CN=あなたのURL" \
-reqexts SAN \
-拡張機能SAN \
-config <(cat /etc/ssl/openssl.cnf \
<(printf "[SAN]\subjectAltName=DNS:your-url"))
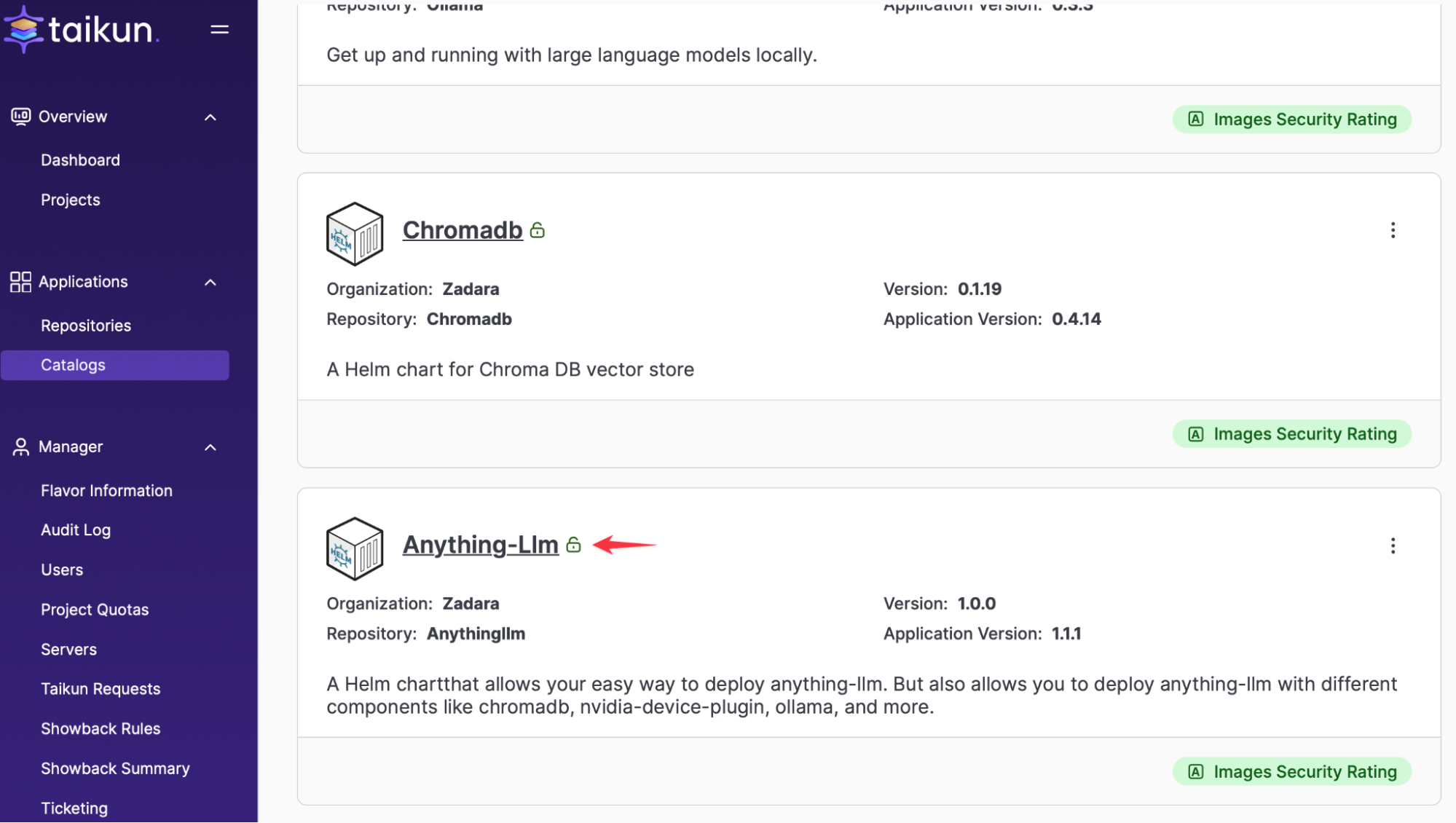
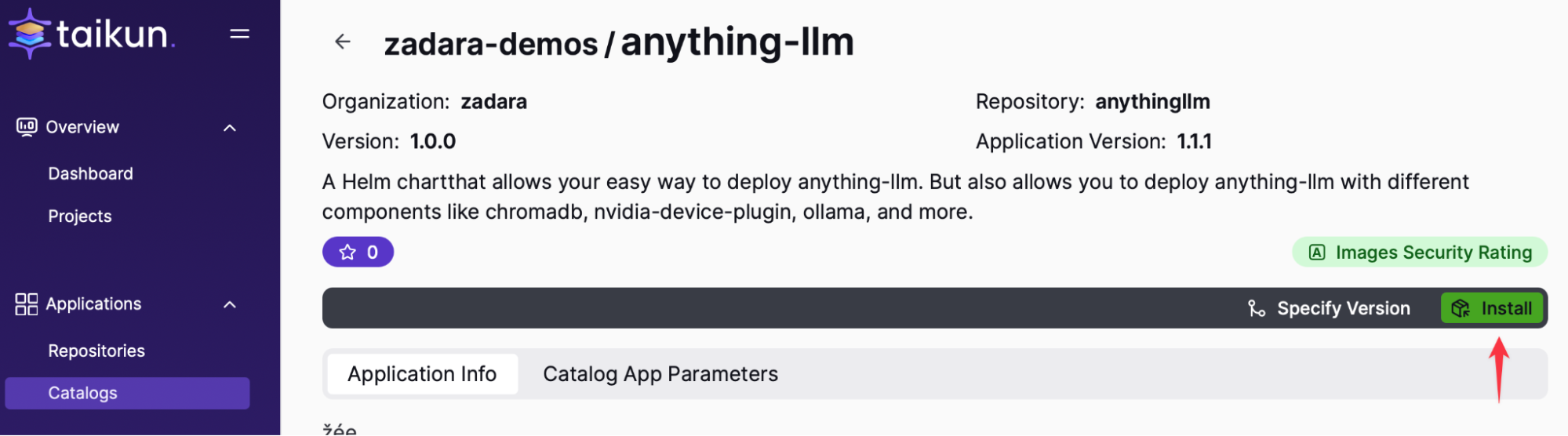
CloudworksにAnythingLLMをインストールします。
簡単にするために、 ヘルムチャート これにより、AnythingLLM、ChromaDB、Ollamaの3つのコンポーネントがすべて統合されます。Helmチャートには2つの名前空間が必要です。XNUMXつはバックエンドサービス用、もうXNUMXつはフロントエンドポータル用です。バックエンドの名前空間の名前は「llm-backend」とし、フロントエンドの名前空間は自動的に「anythingllm」となります。
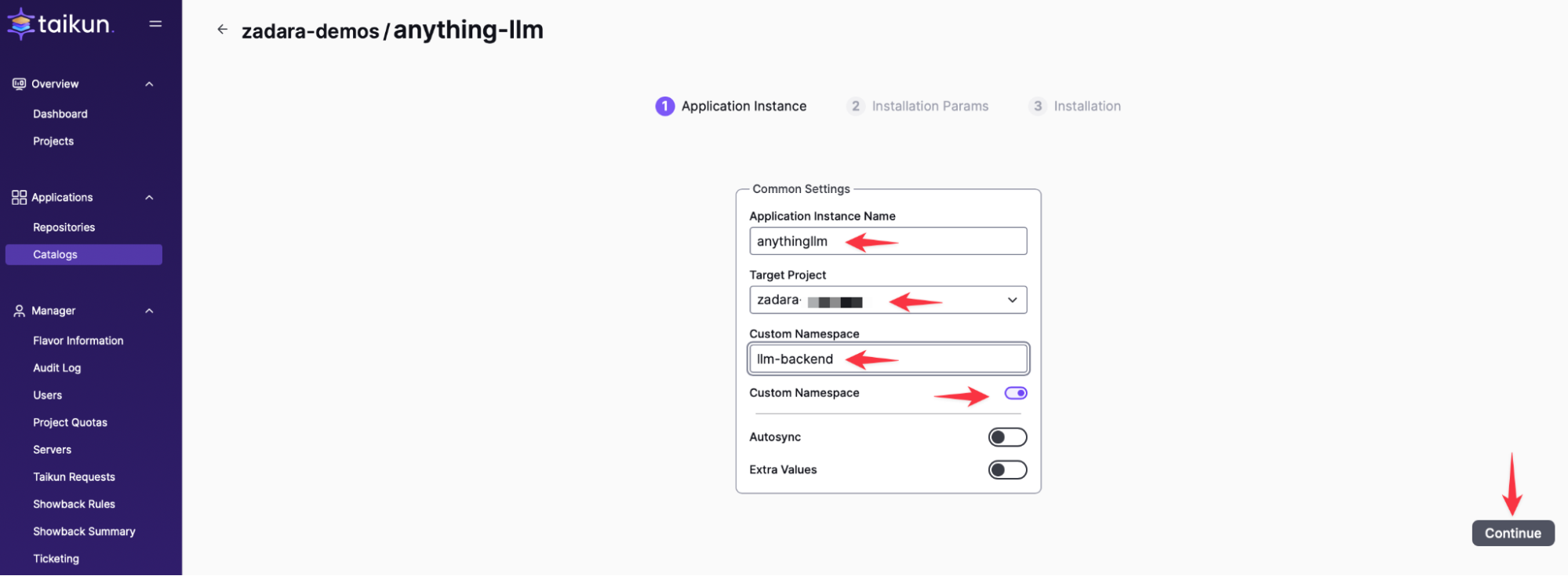
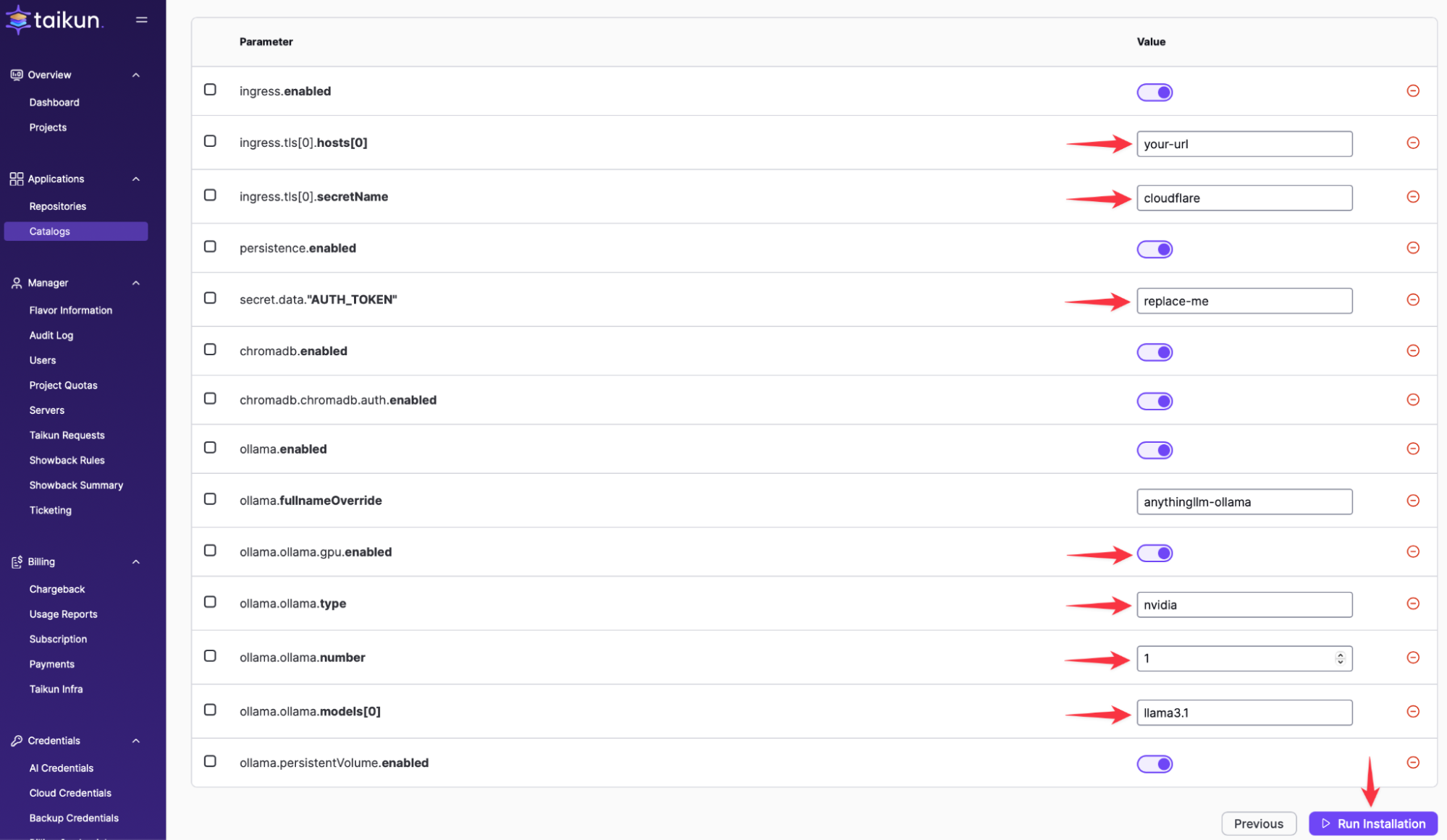
DNS と特定の環境設定に基づいてすべての設定を変更します。
GPUの種類と数に応じてパラメータを更新してください。OllamaはAMD、NVIDIA、INTELのGPUをサポートしています。このデモでは、単一のワーカーノードでL40 NVIDIA GPUをXNUMXつ使用しました。
AnythingLLMをカスタマイズ:
ここで、証明書を Kubernetes にアップロードします。
証明書をアップロードするには、次のコマンドを使用します。
kubectl create secret tls cloudflare --key your-key.key --cert your-cert.crt -n anyllm
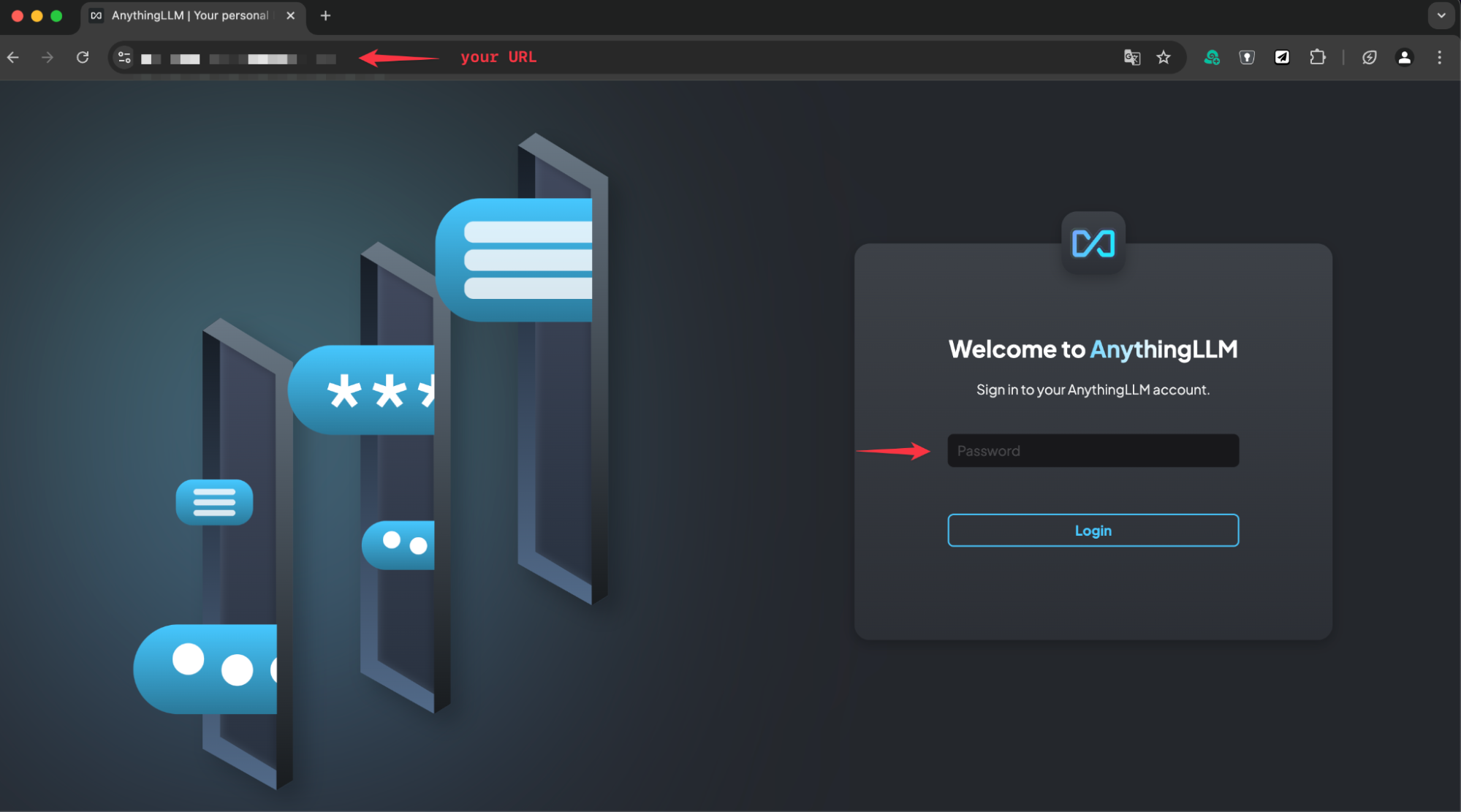
これが完了したら、ブラウザを開いてAnythingLLMにログインする準備が整います。前の手順で設定したURLを使用してください。
初期パスワードは「secret.data.AUTH_TOKEN」で定義されており、この例では「replace-me」です。
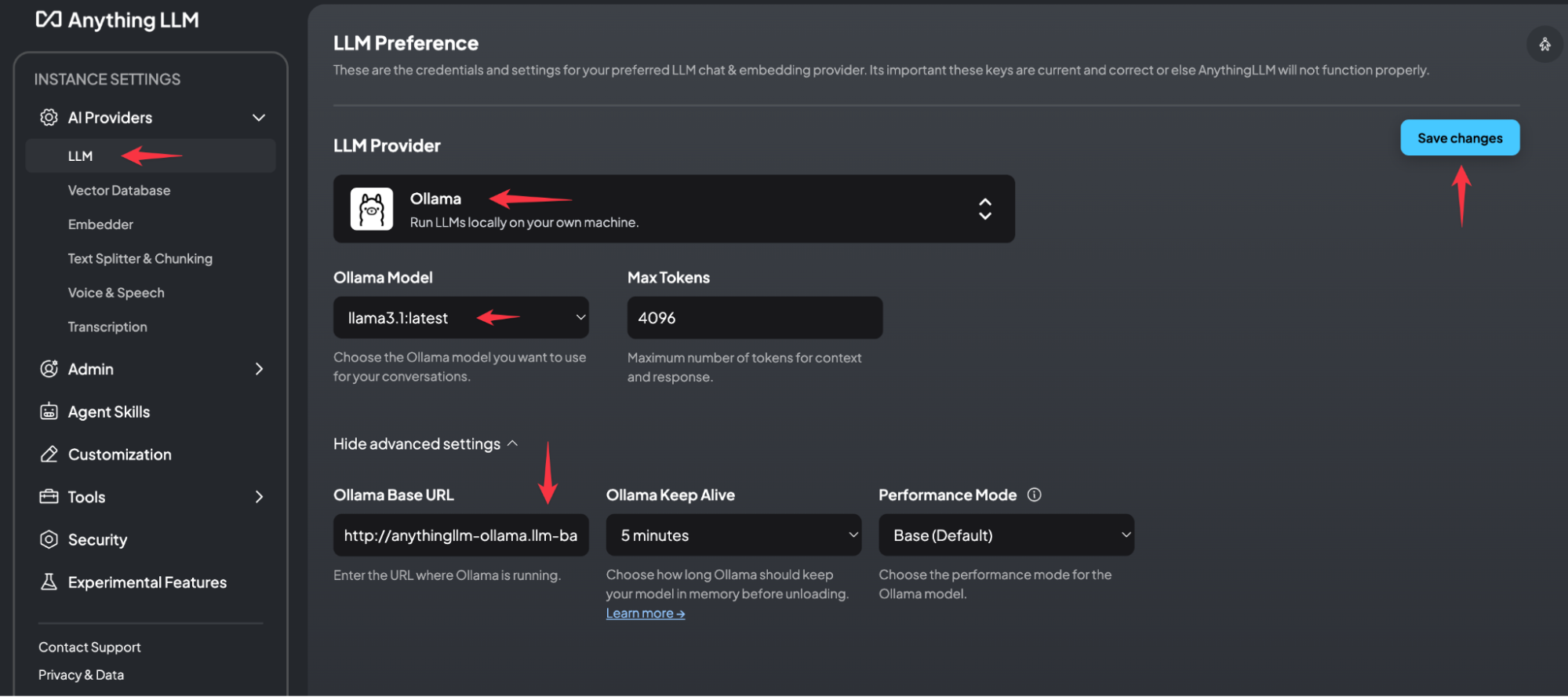
まず、LLMプロバイダーを定義する必要があります。この例では、すべてをまとめてインストールし、Ollamaはllm-backend名前空間に配置されています。
使用するURLは http://anythingllm-ollama.llm-backend.svc.cluster.local:11434. URL が正しい場合、システムは自動的に Ollama モデルを見つけます。
次に、ベクター データベースの定義が必要です。
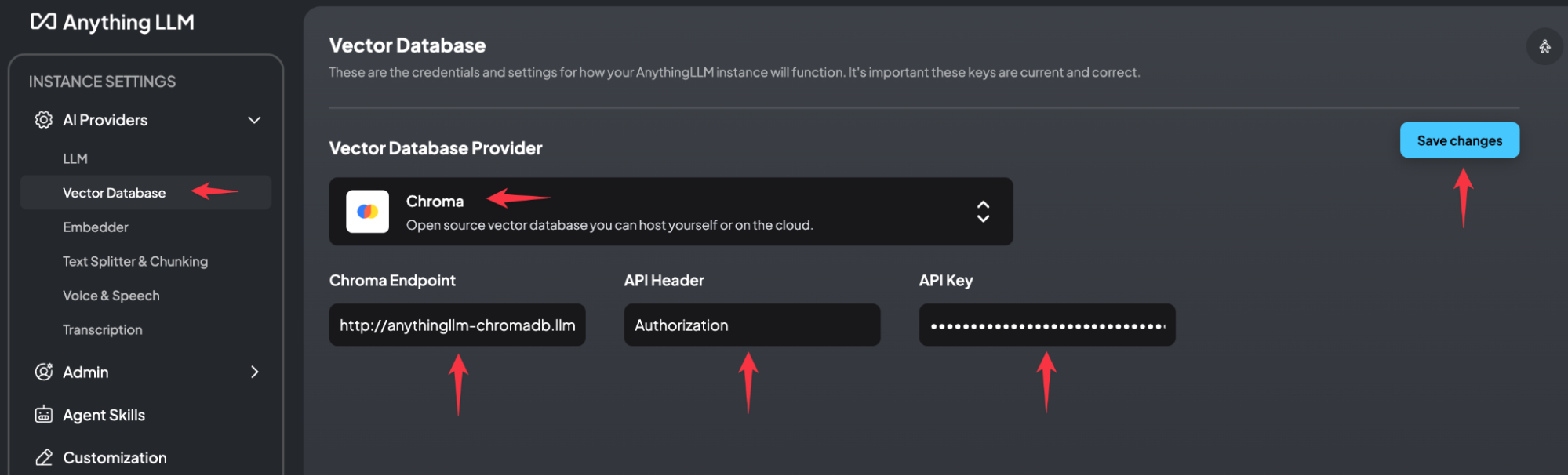
使用するURLは http://anythingllm-chromadb.llm-backend.svc.cluster.local:8000
デフォルトの API ヘッダーは Authorization であり、API キーは次のコマンドで取得できます。
kubectl でシークレット chromadb-auth -n を取得する
llm-backend -o jsonpath="{.data.token}" | base64 --decode
これで、Taikun CloudworksとZadaraで独自のPrivateGPTを実行できるようになります。
結論
最新のアプリケーション展開に Zadara 上の Taikun CloudWorks を活用することで、運用上のオーバーヘッドを大幅に削減し、最も重要なこと、つまり優れた IT サービスの提供に集中できます。
直感的なインターフェース、事前構成されたテンプレート、強力な管理機能を備えた Zadara はインフラストラクチャの複雑さを解消し、Taikun CloudWorks はこれに基づいてアプリケーション展開を構築することで、ワークフローを合理化し、効率性を高めることができます。
データの総合的な力を活用して、独自の AI 展開からさらなるビジネス価値を提供できます。



