

Welcome to the fourth in our new blog series on Kubernetes! In this series, we explore the world of Kubernetes deployment on Zadara, and how it can be used to manage containerized applications in our AWS-compatible cloud. Whether you’re new to Kubernetes or an experienced user, this series will provide you with valuable insights and best practices for managing your containerized applications in the Zadara cloud. Stay tuned for more exciting content!
This blog post will focus on ensuring the continuity of our Kubernetes workloads – from the simplest snapshotting abilities, through using a mature backup & restore solution and up to a Kubernetes control-plane DR readiness procedure.
Basic snapshotting
In addition to the regular block storage abilities, our EKS-D solution is also pre-configured with Kubernetes snapshotting abilities to match the EBS CSI deployment – including having the VolumeSnapshotClass ebs-vsc CRD already set up as the default snapshotter (note the below annotations, we will talk about the k10 annotation later on): 

With the snapshotter deployed, we can manually create a VolumeSnapshot of any given PVC using something like the below YAML specification:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: ebs-volume-snapshot
spec:
source:
persistentVolumeClaimName: ebs-claim
This will create a snapshot of a pre-existing ebs-claim PVC resource, ready to use within seconds (actual time depends on the original volume size):
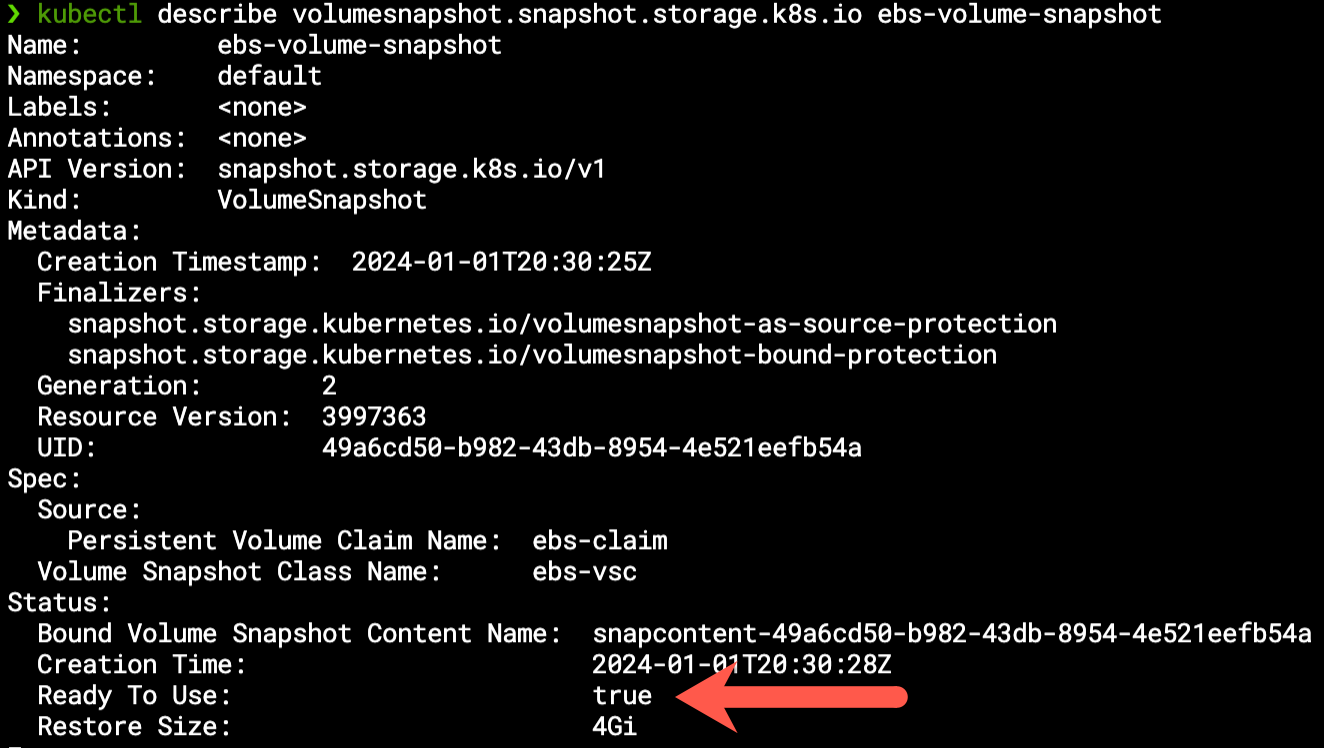
That snapshot can be used in order to recreate a PVC based on its content, using something like the below YAML specification (note the dataSource section):
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ebs-snapshot-restored-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 4Gi
dataSource:
name: ebs-volume-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
It’s worth mentioning that the VolumeSnapshot is bounded to a VolumeSnapshotContent resource, which refers to the actual snapshot resource on the cloud:
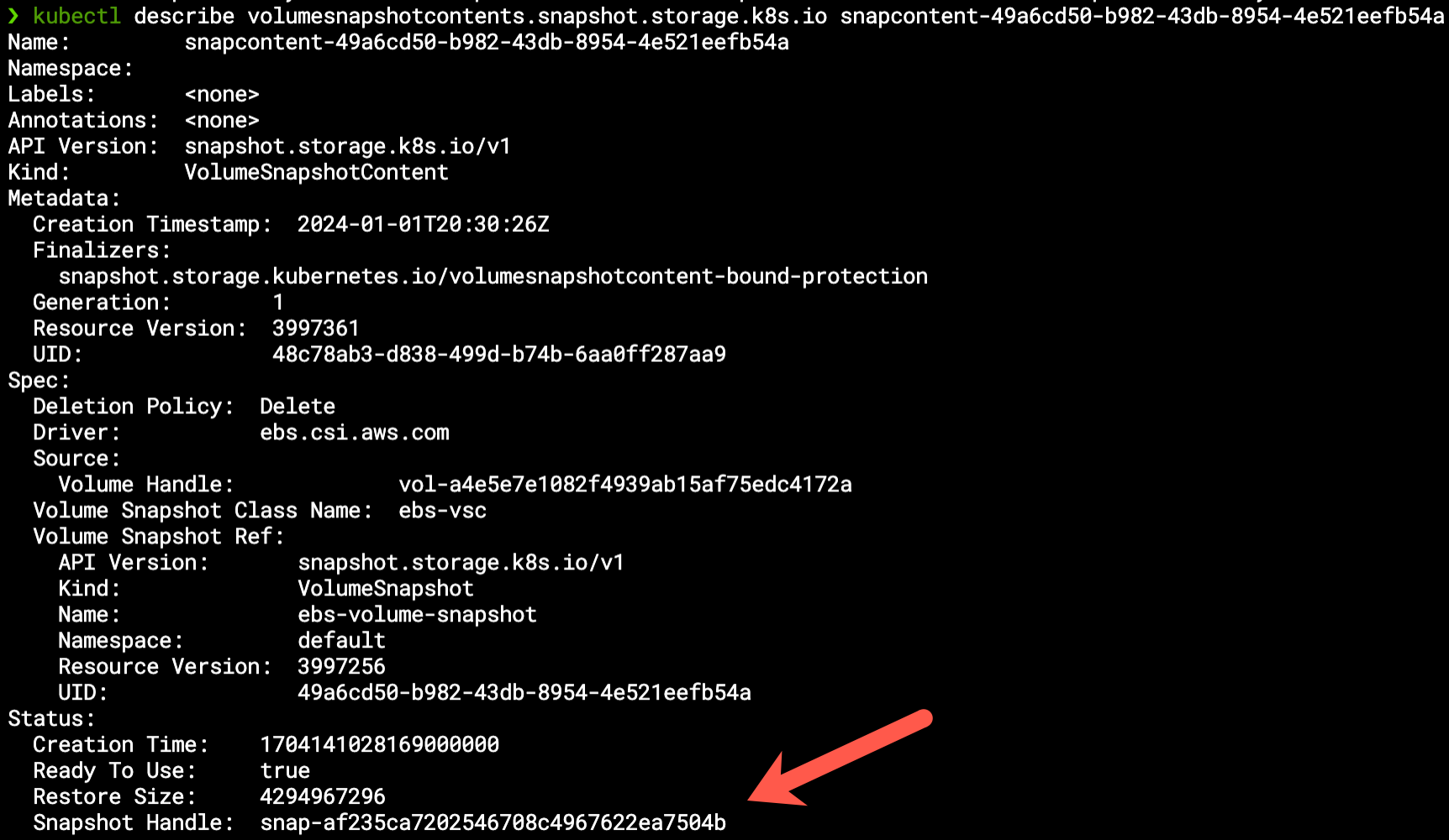
We can see the snapshot cloud resource using the AWS API, Symp API or zCompute GUI console – for example:
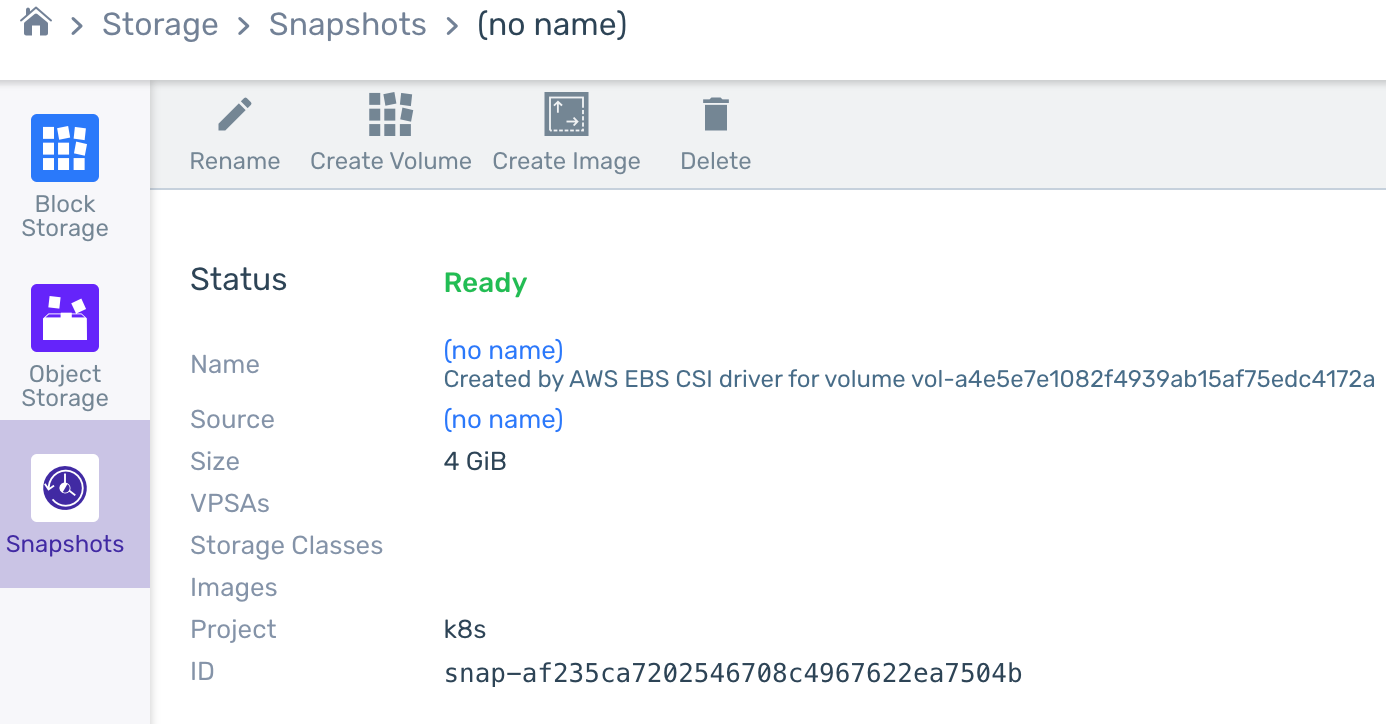
Backup & restore using Kasten K10
For more advanced backup & restore capabilities, we may consider using Kasten K10 – a Veeam product that handles not only the application volumes but its overall Kubernetes specification (pod specs, secrets, etc.), thus allowing to backup and restore the entire application and not just its data.
K10 uses the same snapshotting practices as mentioned in the simplified example mentioned above (we can see the same VolumeSnapshot resources, etc.), however it utilizes the kanister engine to help with various database-oriented use-cases as well as plenty of added functionality that create a great value for Kubernetes administrators looking for an easy way to backup & restore their workloads.
Our EKS-D solution can install K10 for you as part of the deployment automation, or it can be added later on via a simple Helm chart installation – in any case its VolumeSnapshotClass prerequisite is already met with the k10 annotation as previously seen, so we don’t need to modify our cluster before installing it. If you do install K10 by yourself, note the Helm message regarding how to access its dashboard:
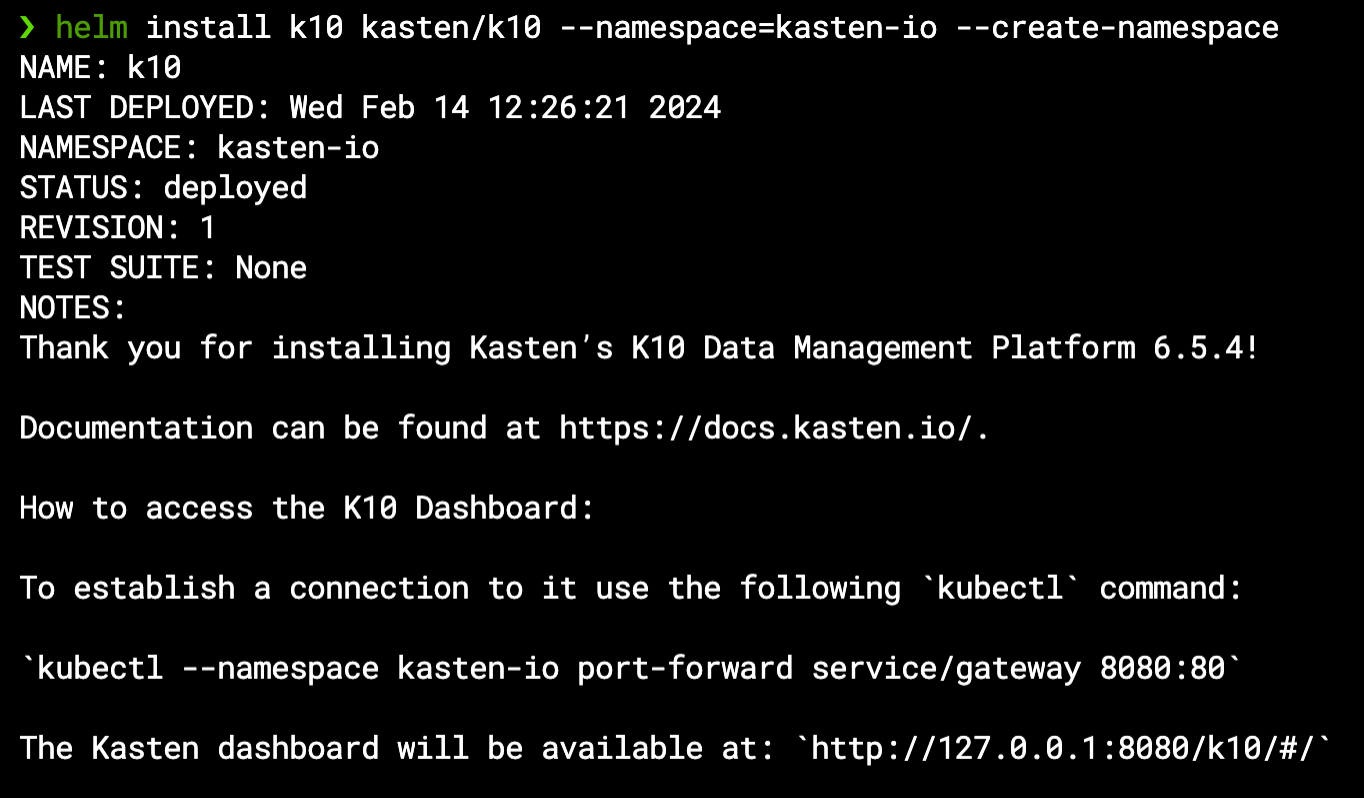
For a basic in-cluster backup & restore operation you don’t require any further setup – just access K10 by port-forwarding its gateway service as mentioned above once all pods are ready:
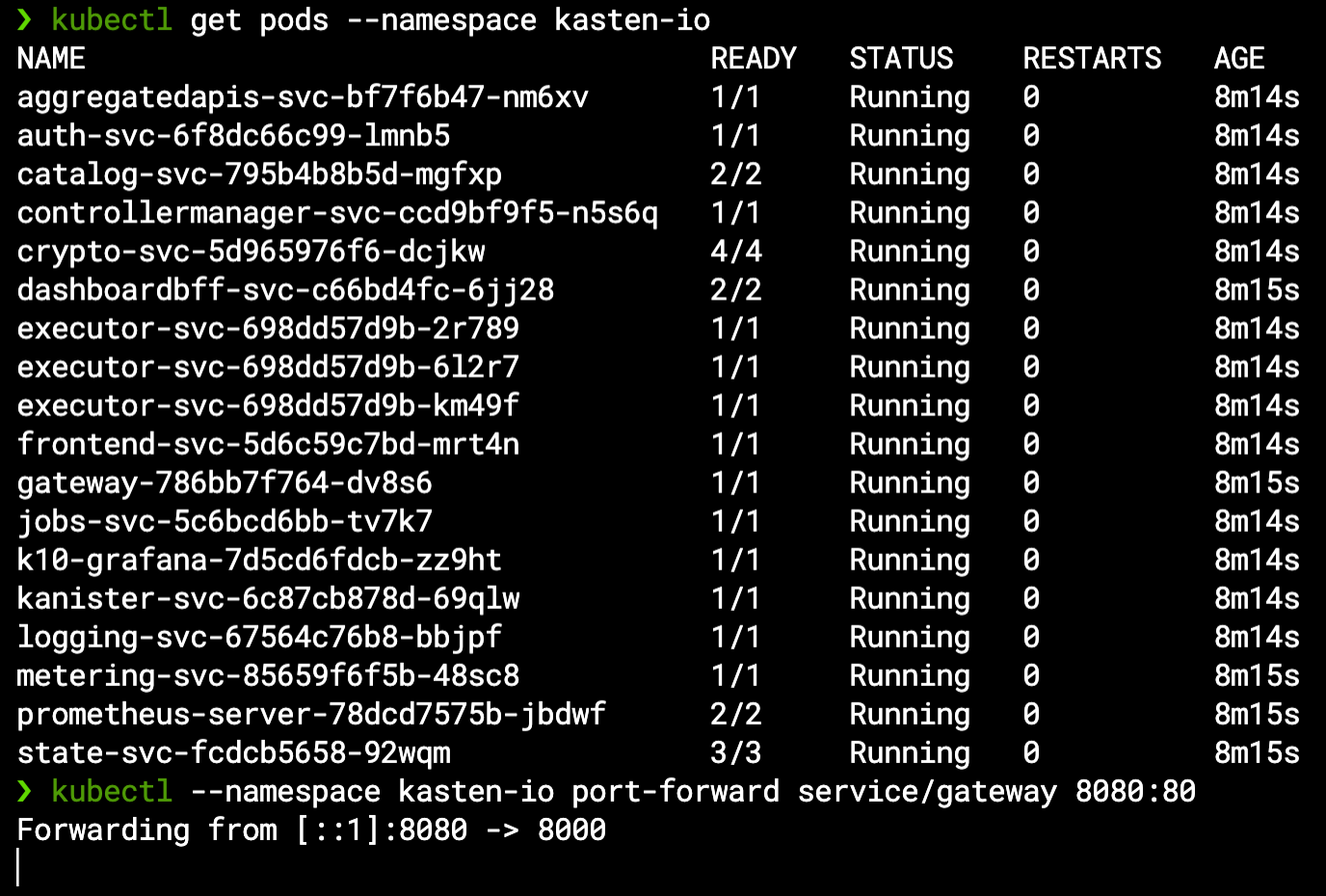
If you wish to expose the dashboard via a Load Balancer, please follow the official documentation for Helm chart usage (and note it will require enabling authentication). In our case we can go right ahead and consume the dashboard via http://localhost:8080/k10/# and accept EULA – please be advised that K10 is only free to use for Kubernetes clusters under 5 worker nodes (refer to their pricing page for more details):
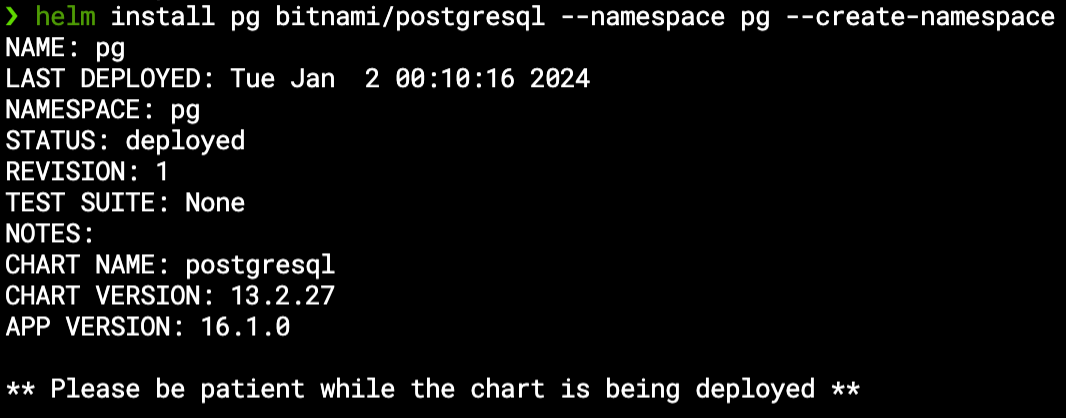
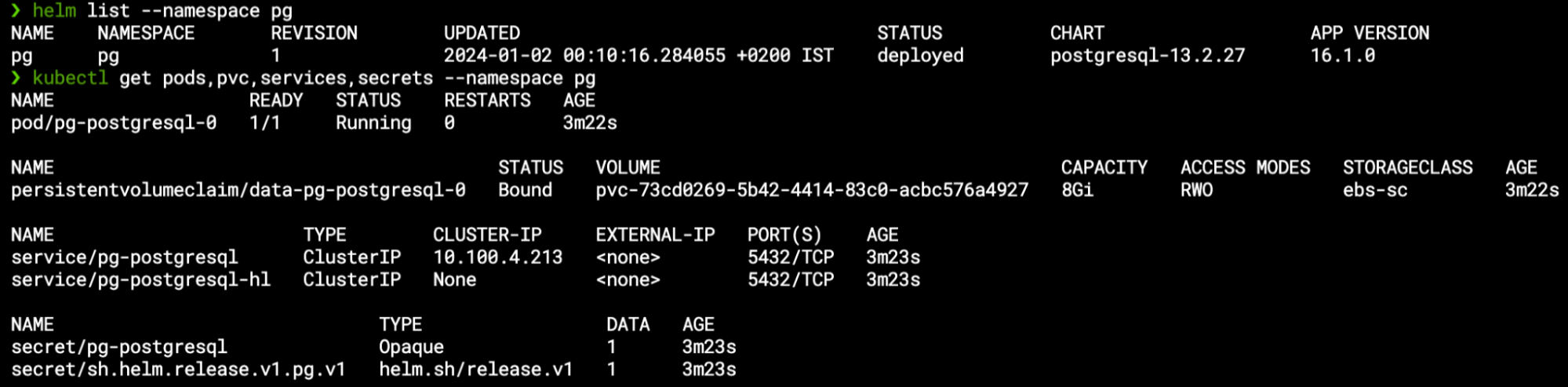
For this demonstration, I have a running PostgreSQL database which I have installed via Helm in the “pg” namespace:
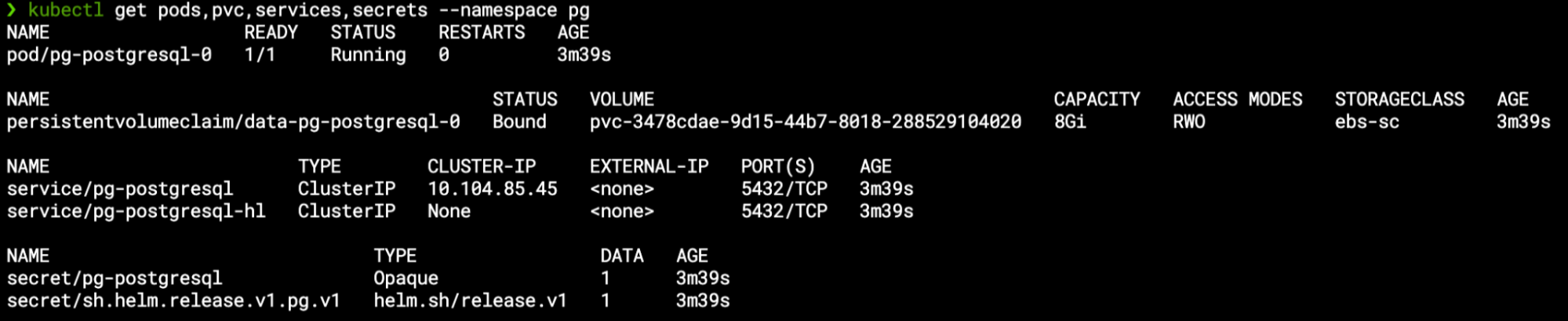
This chart contains several different resources – apart from the StatefulSet itself Helm also deployed the PVC, a Secret (with the admin user’s credentials) and two services for accessing the database:
K10 consolidate all these resources under the pg “unmanaged” application (as we do not have a backup policy for it yet):
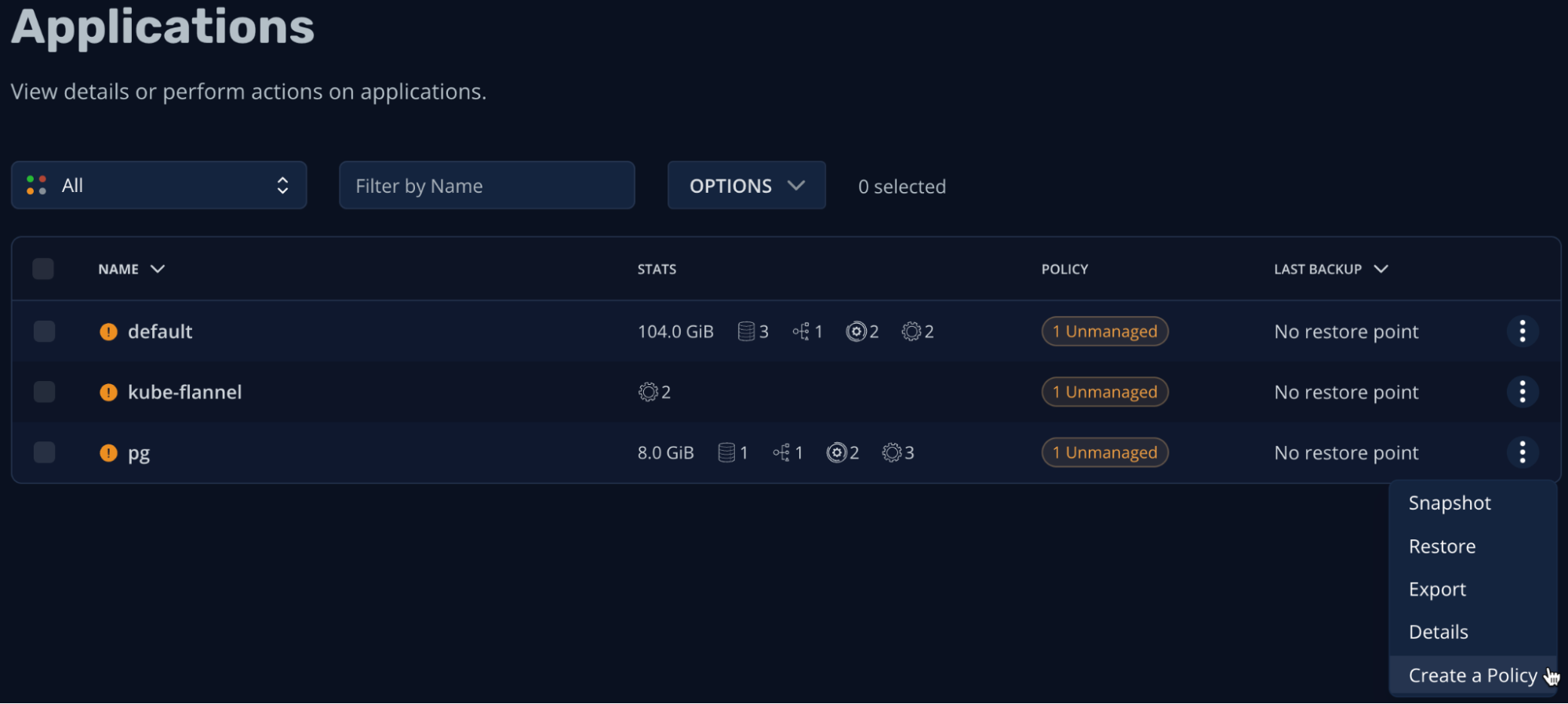
Let’s create a backup policy for the pg application – leaving all default values would create a policy that will take a snapshot of the entire application (all resources including data volumes) on an hourly basis:
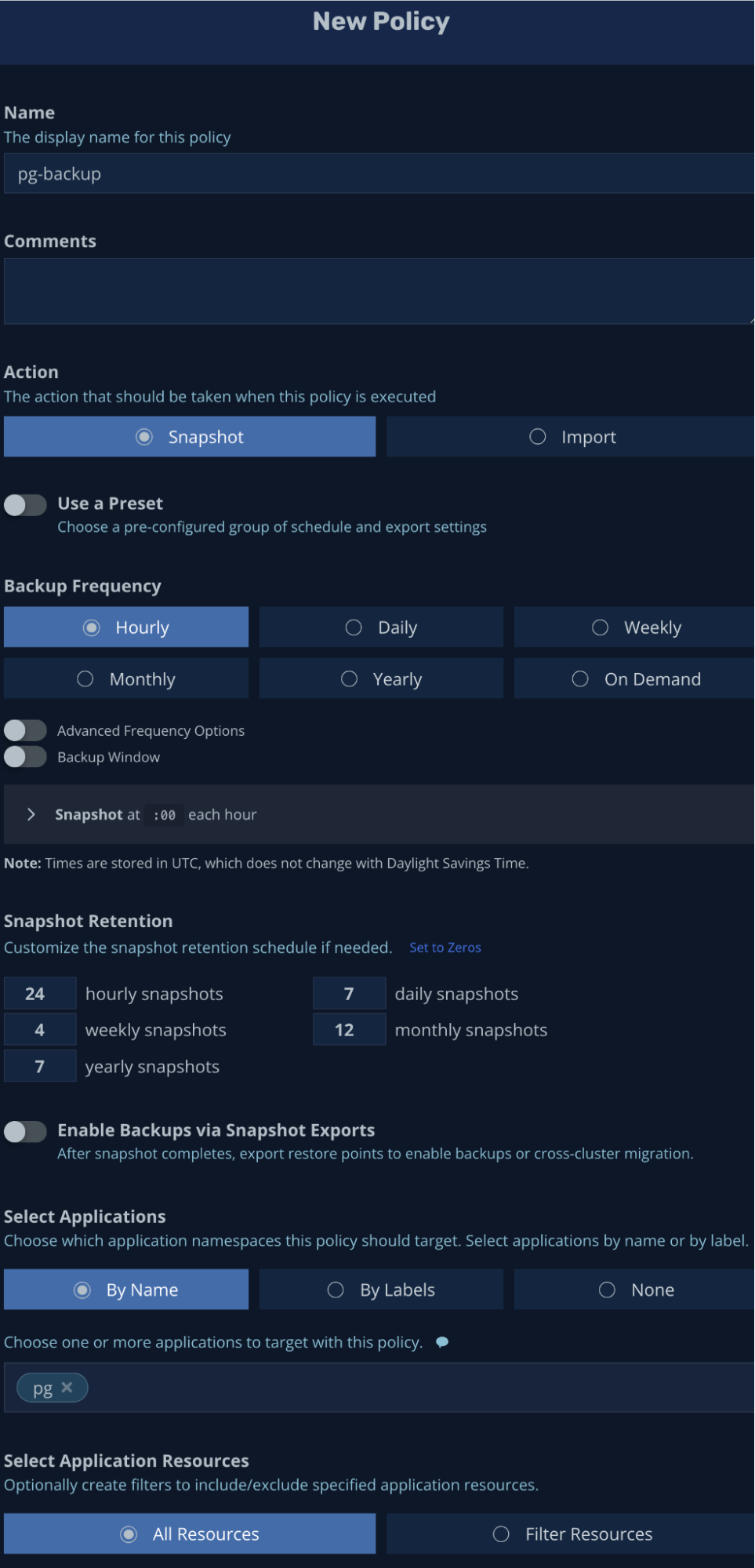
We now have a valid policy (so the application is “managed” by K10) which we can also run on-demand:
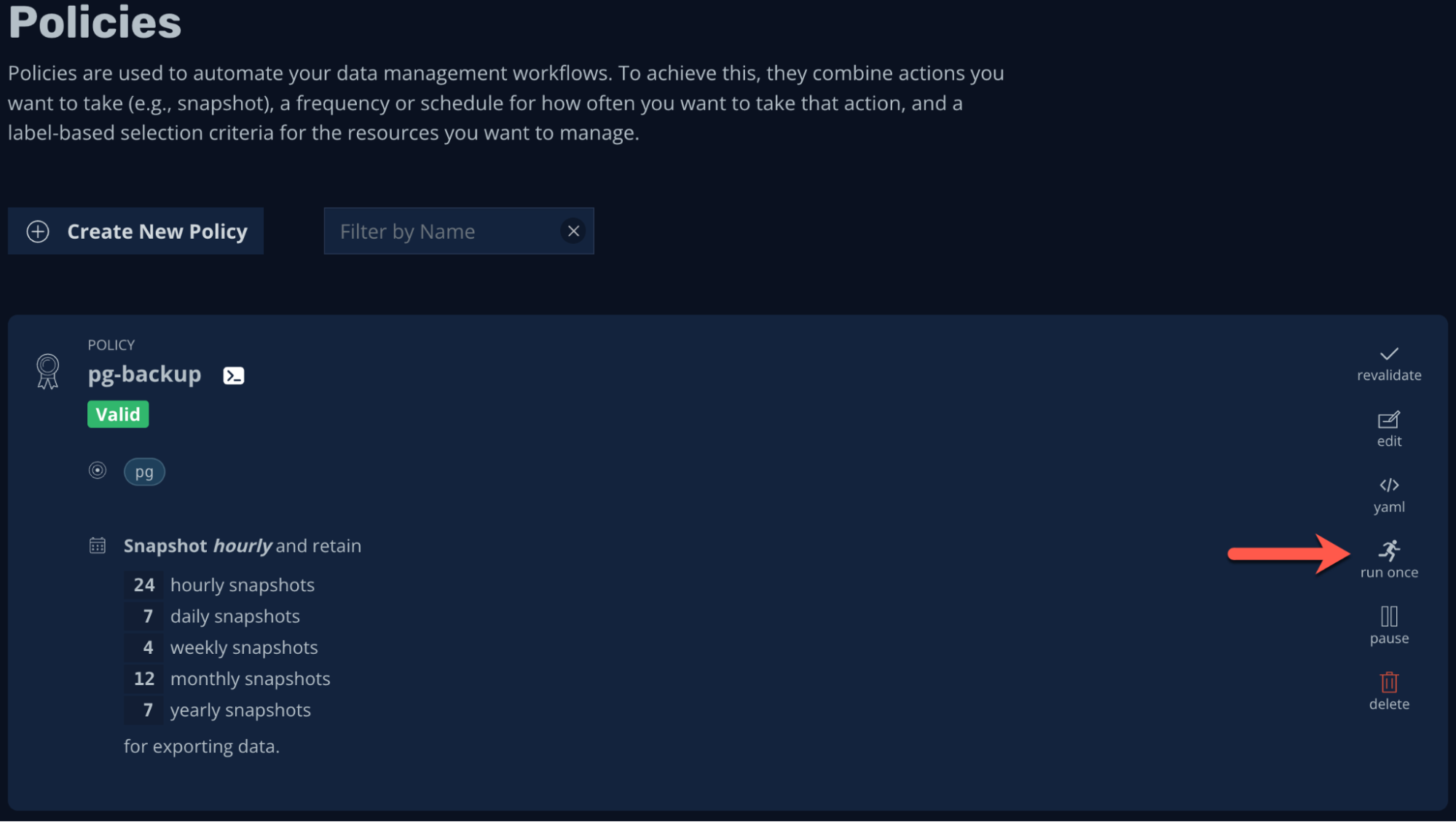
This is the actual backup job (finished within 40 seconds in this simplified case):
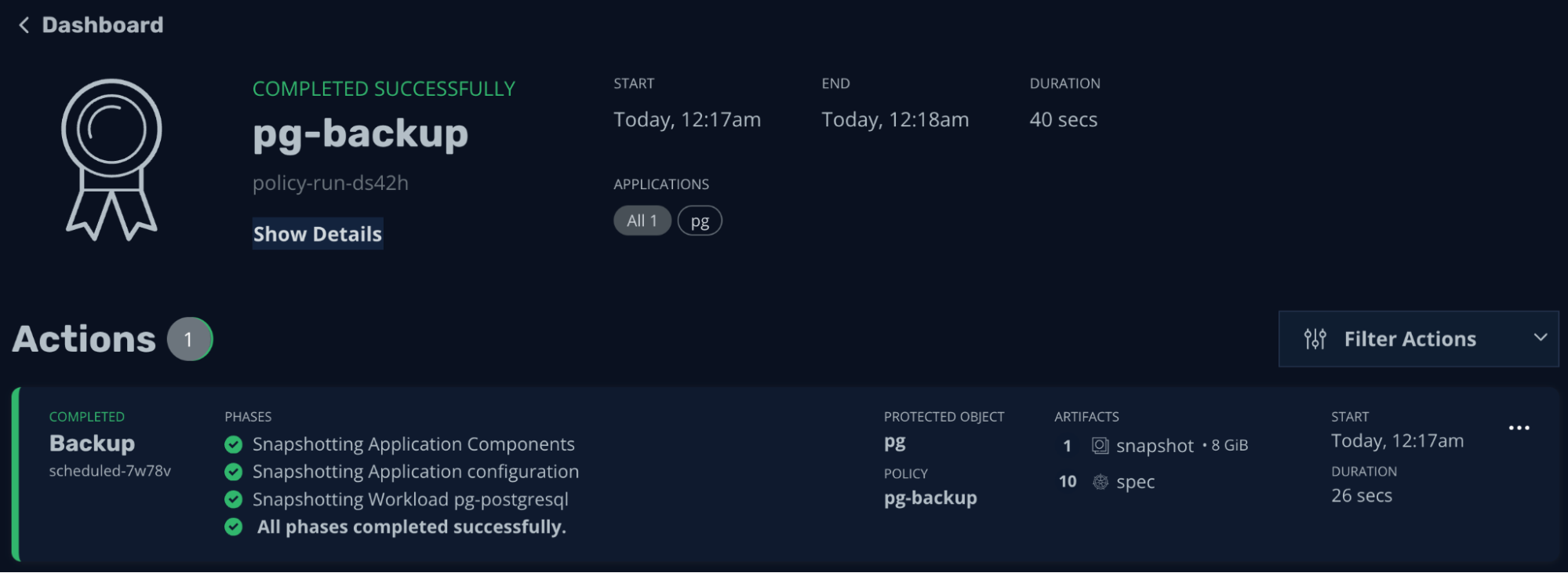
And now for the moment of truth… As the application is managed by K10 (compliant with a backup policy), we will delete it entirely from our Kubernetes cluster using the Helm uninstall command, and since StatefulSet PVCs are not deleted by default, we’ll even make sure that all the resources are gone by manually deleting the PVC:

Since the application is managed by K10, we can simply restore it from the dashboard:
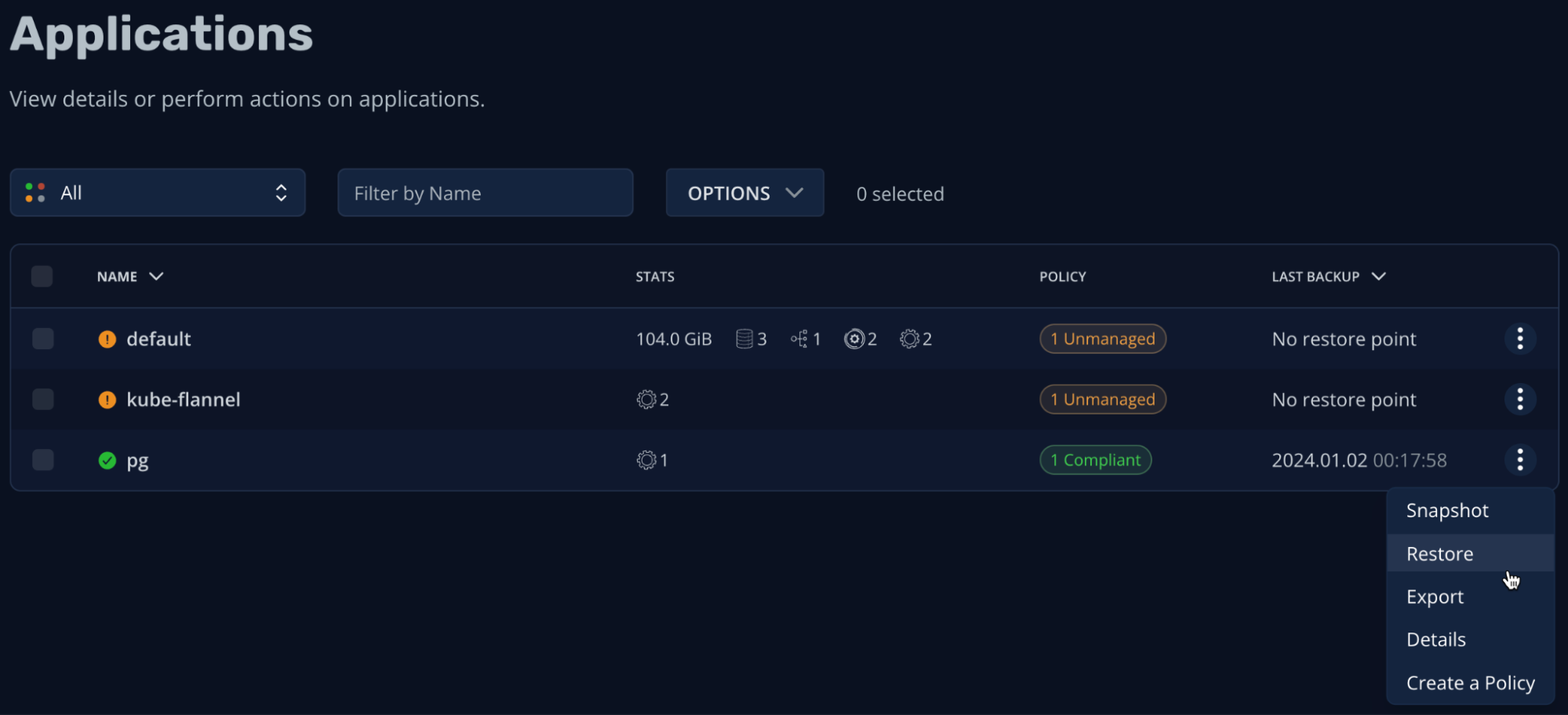
We will be using our only restore point to restore the backup into the same namespace (it can be any other namespace as well):
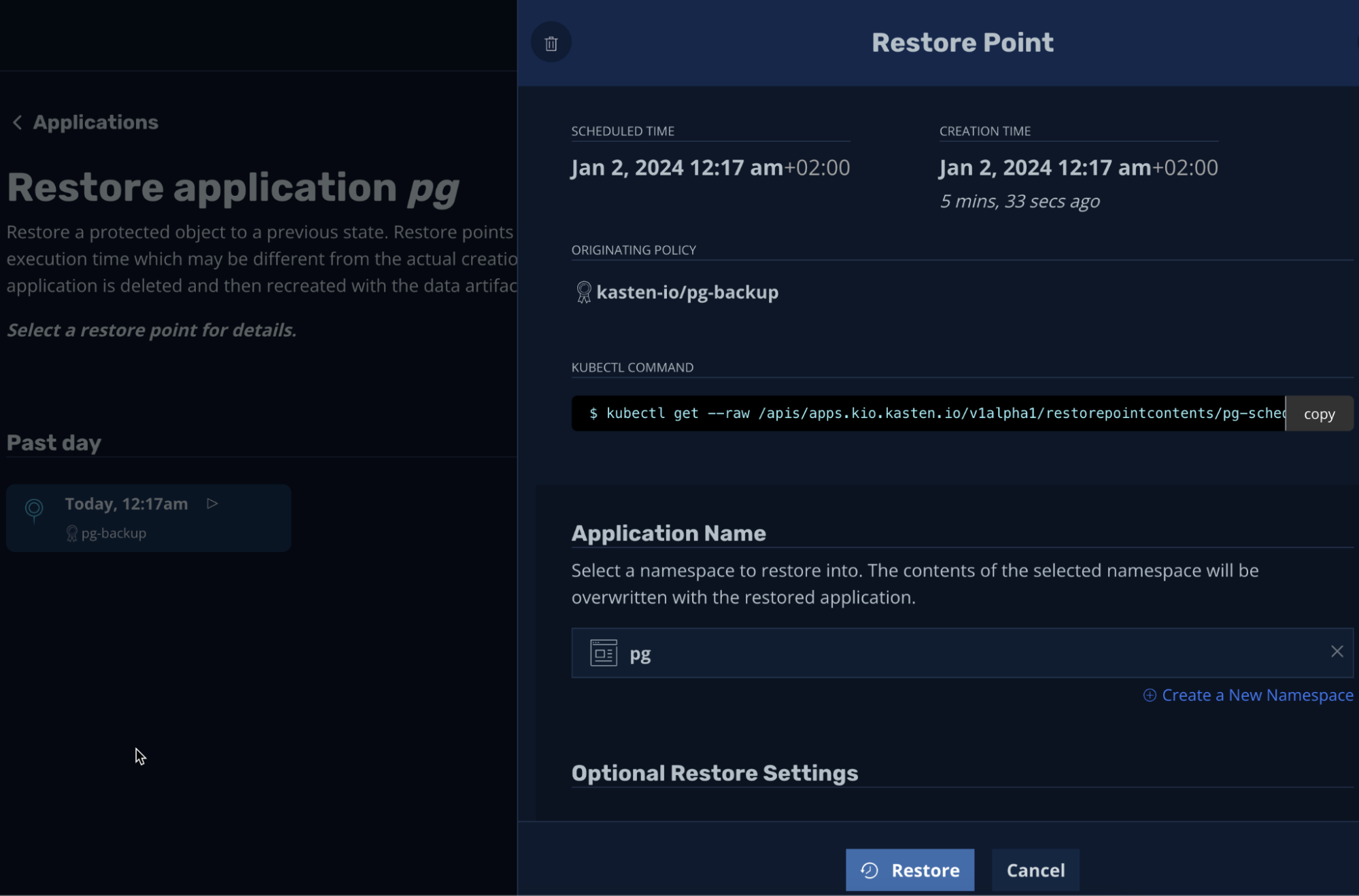
Once the restore job is completed, the application is back online with its original content (new PVC based on the snapshot) and previous configurations – even the Helm annotations are there so Helm thinks it actually deployed it and we can continue to manage the application using Helm:
Exporting backups
We just had a very nice experience restoring our database deployment from a snapshot, however it should be noted that this snapshot was created, stored & restored within our cluster. While this is fine for some restoration use-cases, you might want to consider exporting your backups outside of your cluster, for cases in which your cluster itself is compromised.
For such advanced use-cases, consider integrating K10 with a remote Object Storage solution – for example, Zadara’s Object Storage which is a K10 certified remote storage provider. By exporting our restore points outside the cluster we can protect our applications from cluster-level failures, enable hot/cold DR abilities and even migrate our applications from one cluster into another.
To integrate K10 with Zadara’s Object Storage, we will first need an Object Storage account with user credentials – including S3 access & secret keys, region and API endpoint: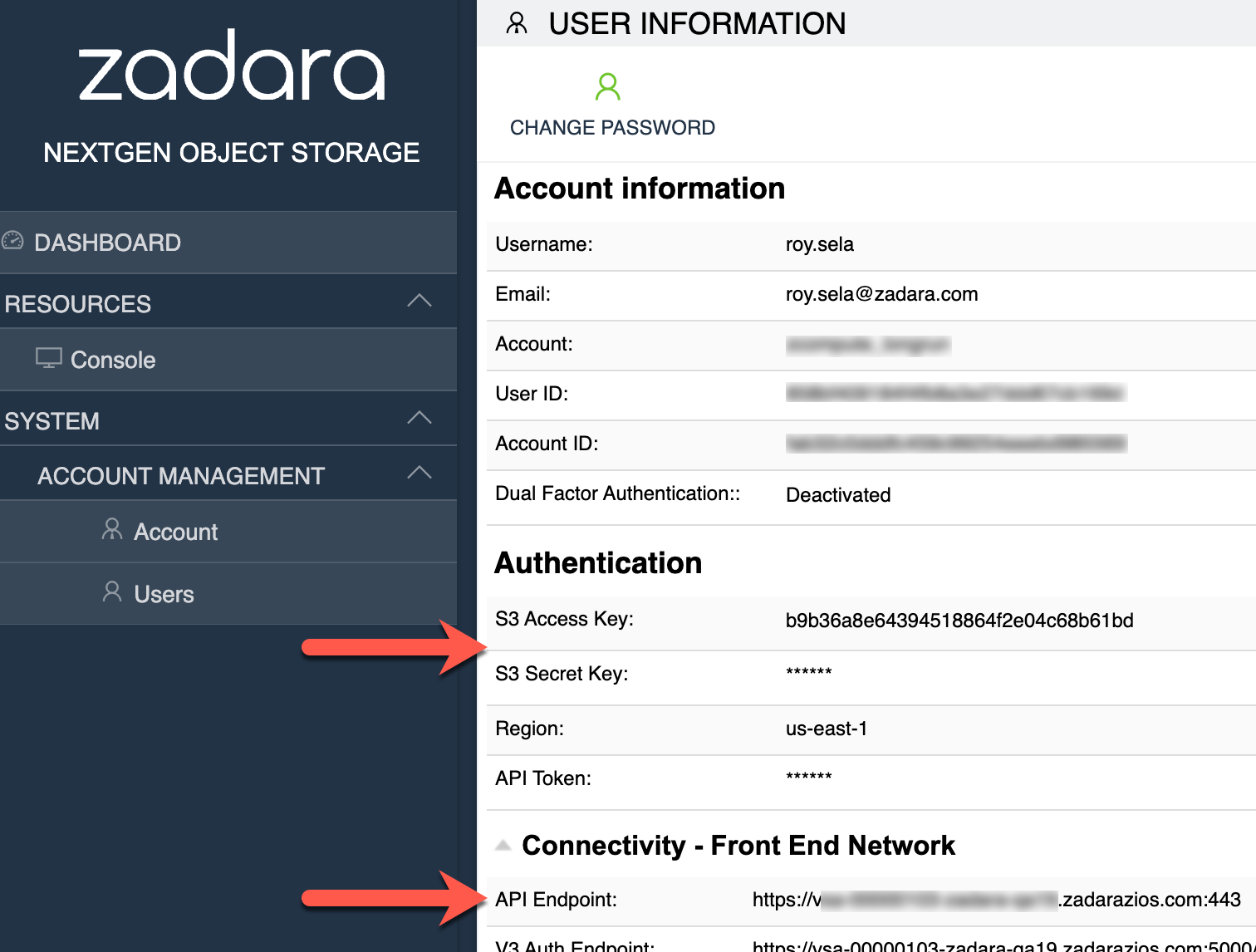
With these details along with a designated bucket, we can create a new S3 Compatible K10 location profile:
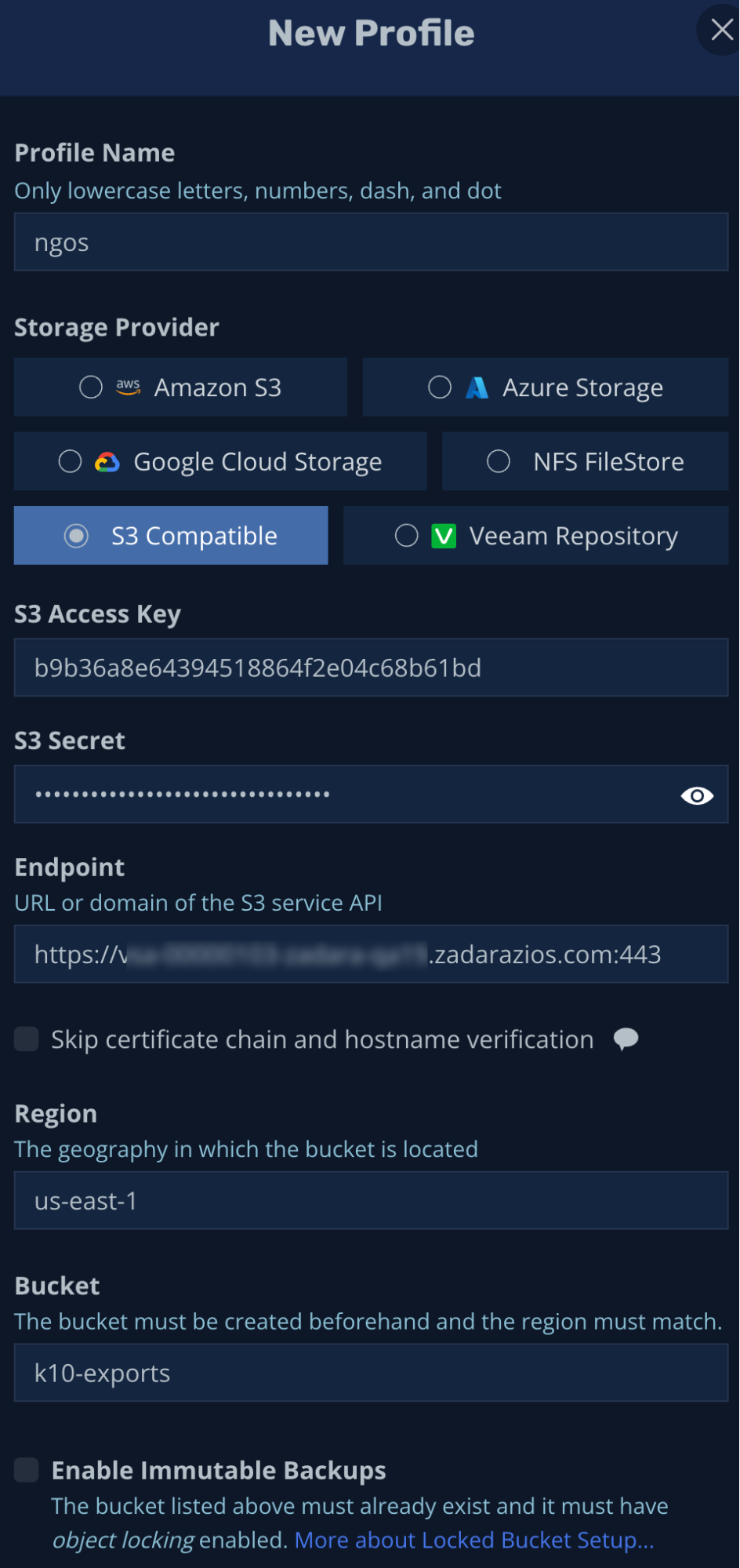
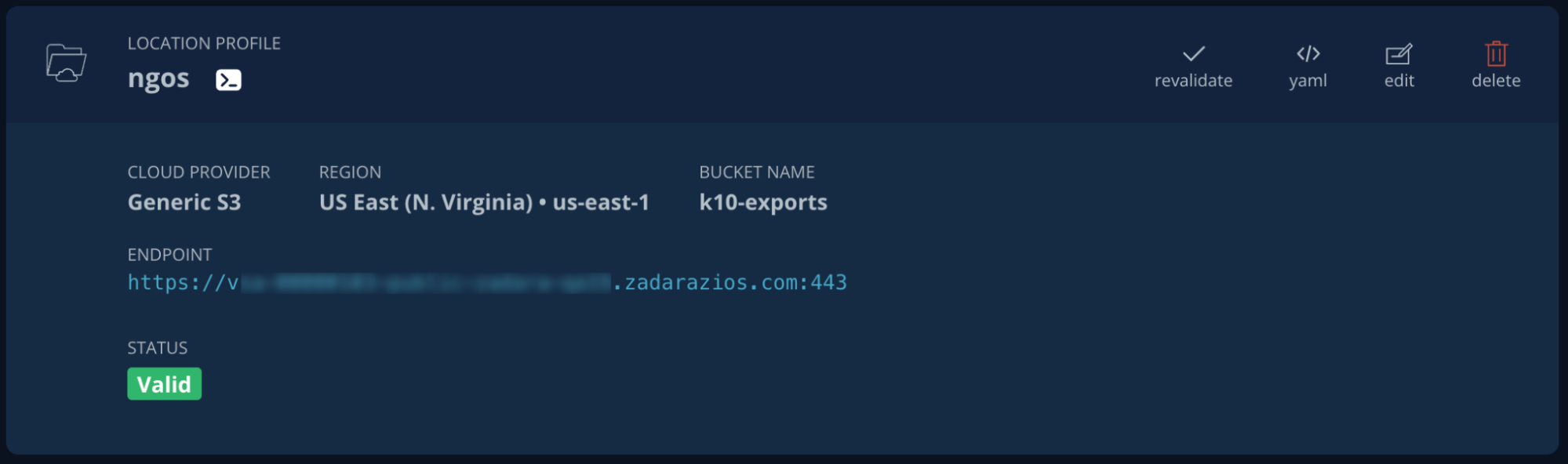
Our location profile is now validated and ready to be used:
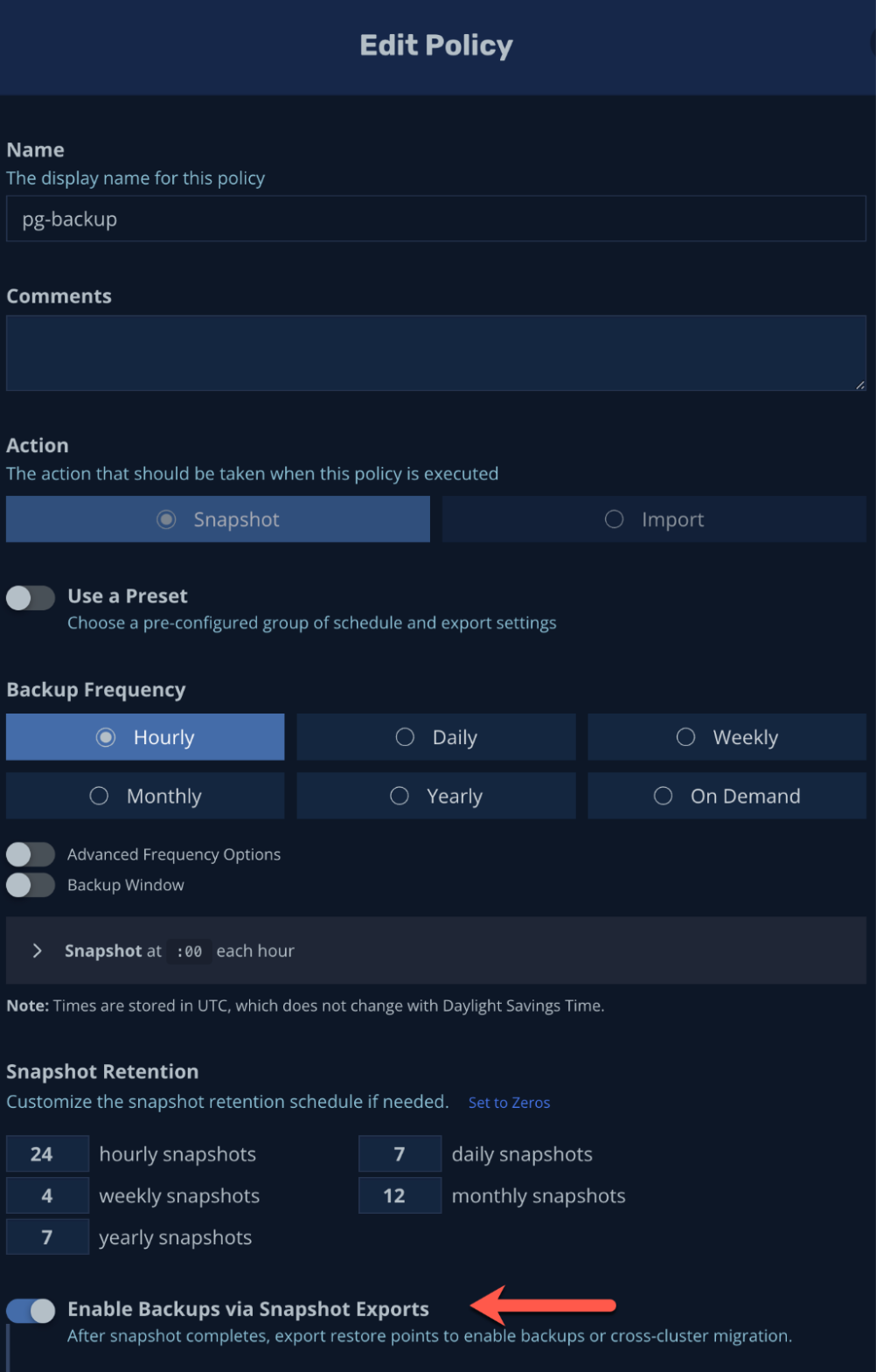
We can create a new export policy or just edit the existing one to include the snapshots exporting ability into our new location profile:
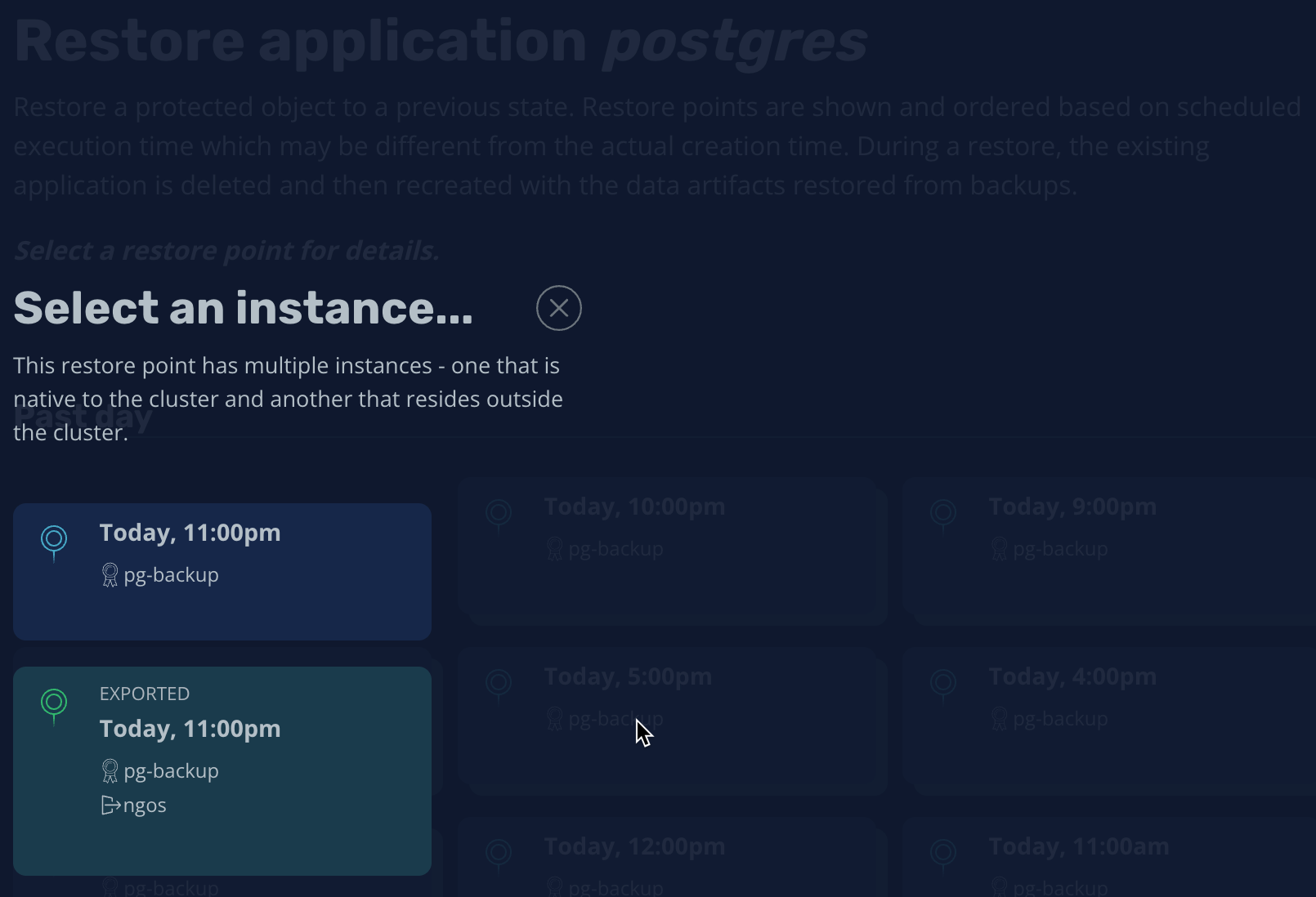
This way our restore points are no longer only stored locally – since they were previously exported, they can also be fetched from outside of the cluster in case we need them:
As mentioned before there are various use-cases that require external backups, like DR scenarios, ransomware protection (with immutable backups) or application migration. Kasten is able to help with all these use-cases and more – including an external DR solution for Kasten itself, but all of these use-cases will be based on the same location profile we have just defined, to be the external backup location.
Control-plane DR readiness
There’s one last continuity feature I wanted to discuss in this blog post, and it involves the Kubernetes control-plane itself. Unlike the K10 backup & recovery use-cases, this scenario deals with cases in which our Kubernetes management-layer was damaged from one reason or another – usually that would be the case of the Kubernetes internal database (ETCD, which stores all Kubernetes configurations) losing its minimal quorum.
Although we protect our Kubernetes control-plane by managing our master nodes (each holding a copy of ETCD) with a dedicated autoscaling group (defaulting to 1 but should be set to 3 nodes for regular high-availability deployments), there’s always a risk of temporal loss of master nodes which can brick our cluster’s management-layer for good, even if the autoscaling group self-heals the actual master nodes afterwards.
Such situations require manual intervention as we need to restore ETCD to recover the cluster itself, and exactly for such cases our EKS-D solution contains a built-in ETCD backup procedure – saving a periodical snapshot of the Kubernetes database that can be used to recover the control-plane if we ever need to.
By default, the backup is only stored locally (within each master node) in the same /etc/kubernetes/zadara directory that stores everything related to the EKS-D solution. The backup name will reflect the hostname as well as its instance id, and we can validate its content via the etcdutl snapshot status command:

While this local backup might be good enough for some use-cases (for example when losing 2 out of 3 master nodes, but the third one can be used for restoring the quorum), the only real solution for such DR use-case would be to store these backup files outside of our cluster – very similar to what we did with the K10 exports.
To accommodate this requirement, the EKS-D solution can be configured to export the local ETCD backups into a remote Object Storage solution, such as Zadara Object Storage or AWS S3. You may either configure it as part of the initial automated deployment variables (more about that in the next blog post), or do it as a post-deployment operation, by specifying the remote location credentials within the zadara-backup-export Kubernetes secret (see the details here).
For now, let’s just create the Kubernetes secret and see how it affects our continuous ETCD backup:

Starting from the next bi-hourly backup cycle, in addition to creating the local backup we will now also export it to Zadara’s Object Storage – as can be seen on every master node’s etcd-backup.log (note the previous local-only backup log entries, versus the last invocation which also included the export):
From the Object Storage side (whether Zadara’s Object Storage or AWS S3) we can see the exports from all of the master nodes – note they will appear under a folder with a name that will be prefixed with the cluster name and also a unique identifier (just in case there are other clusters with the same name):

Be aware that while this solution will preserve the ETCD backups from all master nodes, there is a retention threshold (set to 100 backup files by default), so for a 3 master nodes setup you will typically get around 2-3 days worth of ETCD backup while a single master node’s backups will be retained for over a week.
While I hope you will never have to use these backups, the restore operation is quite simple (as described here in our documentation) – essentially you will have to scale down your masters ASG to a single node, copy one of the ETCD snapshots into that instance, use the etcdutl snapshot restore command to restore the database and restart the ETCD pod with a reset flag – your cluster will then be accessible again and you will need to restart ETCD again without that flag and scale up your masters ASG to its normal capacity.
Final thoughts
In this blog post we’ve gone through various backup & restore options for our EKS-D solution, as they are essential for running production-grade workloads using Kubernetes on Zadara, but we didn’t really set a production-grade cluster – we just used an out-of-the-box setup… In the next blog post we will cover some non-default configurations and other optional customization features that may be required for production-grade Kubernetes clusters – stay tuned!



